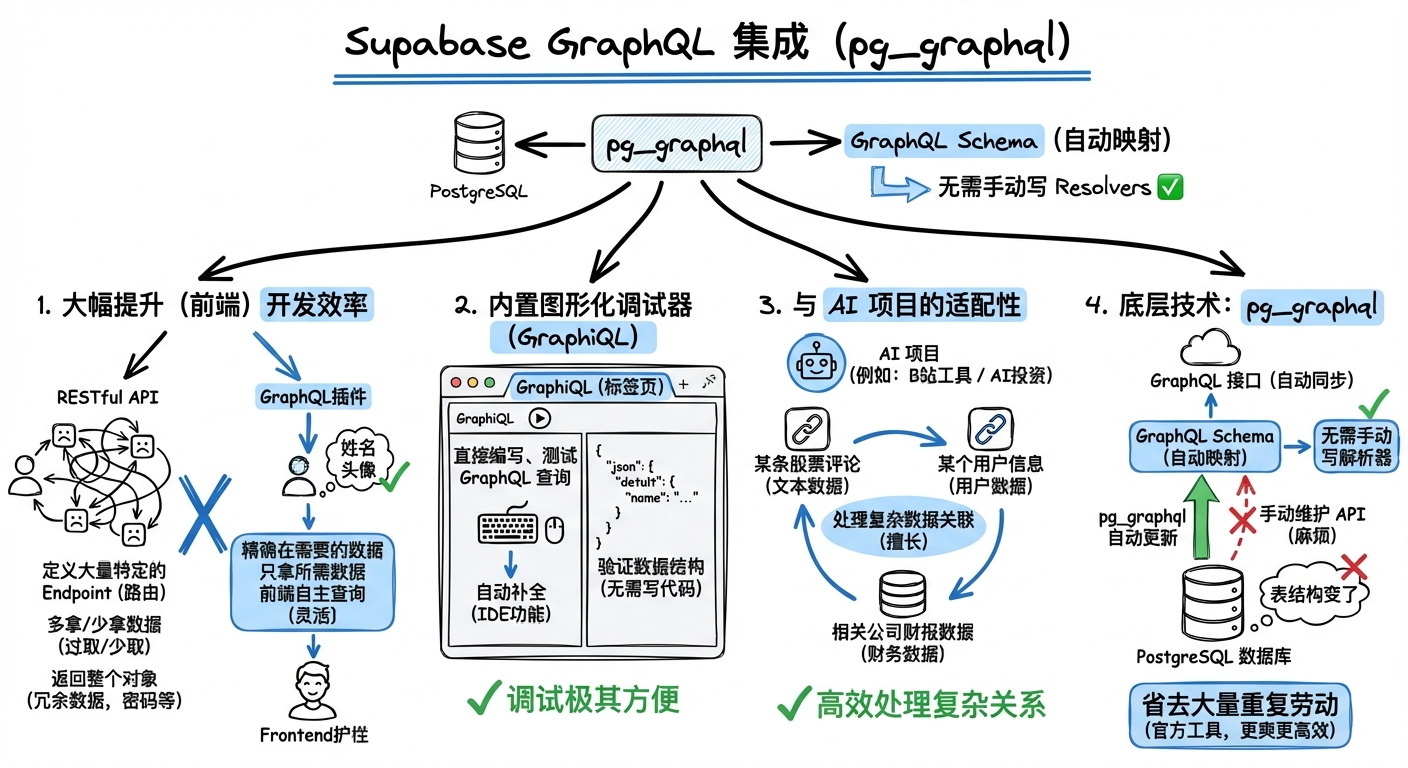
你的这个理解非常敏锐且到位。**从某种程度上说,GraphQL 的本质确实可以被看作是一个高度通用的、自动化的 Controller 层。**
在传统的 MVC 架构中,Controller 负责接收请求、解析参数、调用 Service 层并返回特定格式的数据。而 Supabase 的 GraphQL 集成通过 `pg_graphql` 实际上把这一层“通用化”了。
我们可以从以下几个维度来拆解这个“灵活的 Controller”:
### 1. 从“固定路由”进化到“动态逻辑”
- **传统 Controller**:你需要为每个业务场景写特定的接口(如 `GET /users_with_posts`)。每一个新的前端需求,往往都要后端去修改或新增 Controller 代码。
- **GraphQL 模式**:它提供了一个**单一的入口(Entry Point)**。这个“Controller”不再由你手写,而是由 `pg_graphql` 根据你的数据库表结构(Schema)自动生成。它能理解前端发来的所有合规的“查询指令”,并自动翻译成 SQL。
### 2. 核心本质:屏蔽复杂的 SQL 细节
这个“灵活的 Controller”实际上在做两件事:
1. **解析(Parsing)**:解析你发来的 JSON 格式的查询请求。
2. **映射(Mapping)**:将查询请求映射到数据库操作上。
### 3. “灵活”体现在数据裁剪
传统的 Controller 往往是“给什么吃什么”。而这个基于 GraphQL 的层级允许前端决定:
- **字段筛选**:只取需要的列(解决 Over-fetching)。
- **关系嵌套**:一次请求拿回主表和关联表的数据(解决 N+1 查询问题),这在传统 Controller 里通常需要写复杂的 `JOIN` 语句。
---
### 这种“自动化 Controller”的局限性
虽然它很灵活,但你作为产品经理/开发者,也要注意到它和手动写 Controller 的区别:
- **业务逻辑(Business Logic)**:纯粹的 `pg_graphql` 只是数据的搬运工。如果你需要在“查询”之外做复杂的权限校验、发送邮件通知或调用 AI 模型,仅靠这个 GraphQL 层是不够的。你可能还是需要结合 **Database Functions** 或者 **Supabase Edge Functions**(那才是你真正的、带业务逻辑的 Controller)。
- **性能边界**:因为它是动态生成 SQL,对于极其复杂的深度嵌套查询,生成的 SQL 性能可能不如你亲手写的优化 SQL。
**总结:**
它本质上是一个**以数据模型为驱动的、零代码的 Controller 抽象层**。对于你现在的 **AI50** 项目,如果主要是简单的增删改查(CRUD)和复杂的数据展示,用它能极大地缩短你的开发周期。
你现在的 **AI50** 项目是打算直接用这个 GraphQL 接口给前端调用,还是打算在它前面再包一层自己的逻辑?