# 💡Summary
> [!Info]
> 一句话说清楚
>
# 🧩 Cues
# 🪞Notes
## 数据库字段变化
当你点击一个评分按钮,`review_cards` 表里这些字段会更新:
| 字段 | 含义 | 点"忘了" | 点"简单" |
| :------------- | :--------------- | :-------------------- | :------------------- |
| `stability` | 记忆稳定性(天) | 大幅下降(如 10→0.4) | 大幅上升(如 10→45) |
| `difficulty` | 卡片难度(1-10) | 上升 | 下降 |
| `due` | 下次复习时间 | 几分钟后 | 几十天后 |
| `scheduled_days` | 间隔天数 | ~0 | ~45 |
| `state` | 卡片状态 | → Relearning(3) | 保持 Review(2) |
| `reps` | 复习总次数 | +1 | +1 |
| `lapses` | 遗忘次数 | +1 | 不变 |
| `last_review` | 上次复习时间 | 设为现在 | 设为现在 |
---
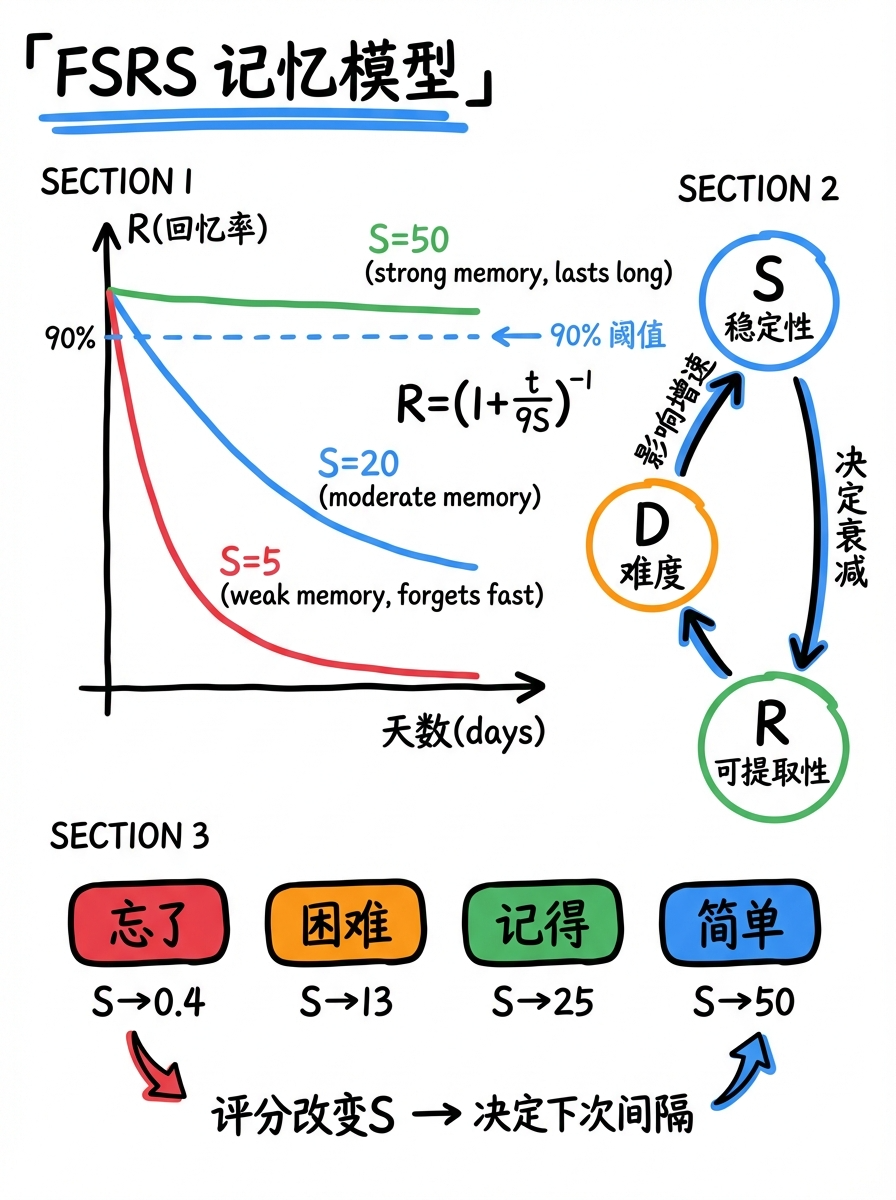
FSRS 的核心模型:记忆的三个变量
FSRS 基于「记忆三组件模型」,用三个变量描述你的记忆状态:
1. Stability (S) — 稳定性
- 定义:经过 $S$ 天后,你的回忆概率恰好降到 90%
- $S=1$ → 1天后就只有 90% 概率记得
- $S=30$ → 30天后仍有 90% 概率记得
- 这是决定"多久后再复习"的核心变量
2. Difficulty (D) — 难度
- 范围 1~10,反映这张卡对你个人的难度
- 点"忘了"→ $D$ 上升,点"简单"→ $D$ 下降
- $D$ 影响 $S$ 的增长速率:越难的卡,$S$ 增长越慢
3. Retrievability (R) — 可提取性
- 你此刻能回忆起来的概率,随时间衰减
- 遗忘曲线公式:$R = (1 + t/(9 \cdot S))^{-1}$
- $t=0$(刚复习完)→ $R=100\%$
- $t=S$ → $R=90\%$
- $t=3S$ → $R \approx 70\%$
---
## 调度逻辑:怎么算下次间隔
下次间隔 = $S \times (\text{desired\_retention}^{(1/\text{decay})} - 1)$
默认 `desired_retention = 0.9`(目标保持 90% 回忆率)。
具体例子(假设当前 $S=10, D=5$):
| 评分 | S 变化 | 下次间隔 | 直觉解释 |
| :------ | :-------- | :------- | :----------------- |
| 忘了(1) | 10 → ~0.4 | 几分钟 | 记忆崩了,从头来 |
| 困难(2) | 10 → ~13 | ~13天 | 勉强记得,小幅增长 |
| 记得(3) | 10 → ~25 | ~25天 | 正常回忆,稳步增长 |
| 简单(4) | 10 → ~50 | ~50天 | 太容易了,大幅拉长 |
---
状态流转
New(0) ──评分──→ Learning(1) ──毕业──→ Review(2)
│
忘了
↓
Relearning(3) ──重新毕业──→ Review(2)
- New→Learning:首次复习,间隔很短(1min, 10min)
- Learning→Review:评分 Good/Easy 后"毕业",进入正式复习周期
- Review→Relearning:在 Review 阶段点了"忘了",退回短间隔重学
- Relearning→Review:重新答对后恢复,但 $S$ 已大幅缩小
---
为什么这样设计?
传统算法(如 SM-2)用固定的 `ease factor` 乘以间隔,问题是:
- 一次遗忘就永久降低 `ease factor`("ease hell")
- 无法区分"忘了一个月前学的"和"忘了昨天学的"
FSRS 的改进:
1. 遗忘后的 $S$ 取决于遗忘前的 $S$ — 之前记得越久,遗忘后恢复越快(记忆残留效应)
2. $D$ 和 $S$ 解耦 — 难度影响增长速度,但不直接决定间隔
3. 可用真实复习数据优化参数 — `review_logs` 表就是为此准备的,未来可以用你的数据训练个性化参数