# 💡Summary
> [!Info]
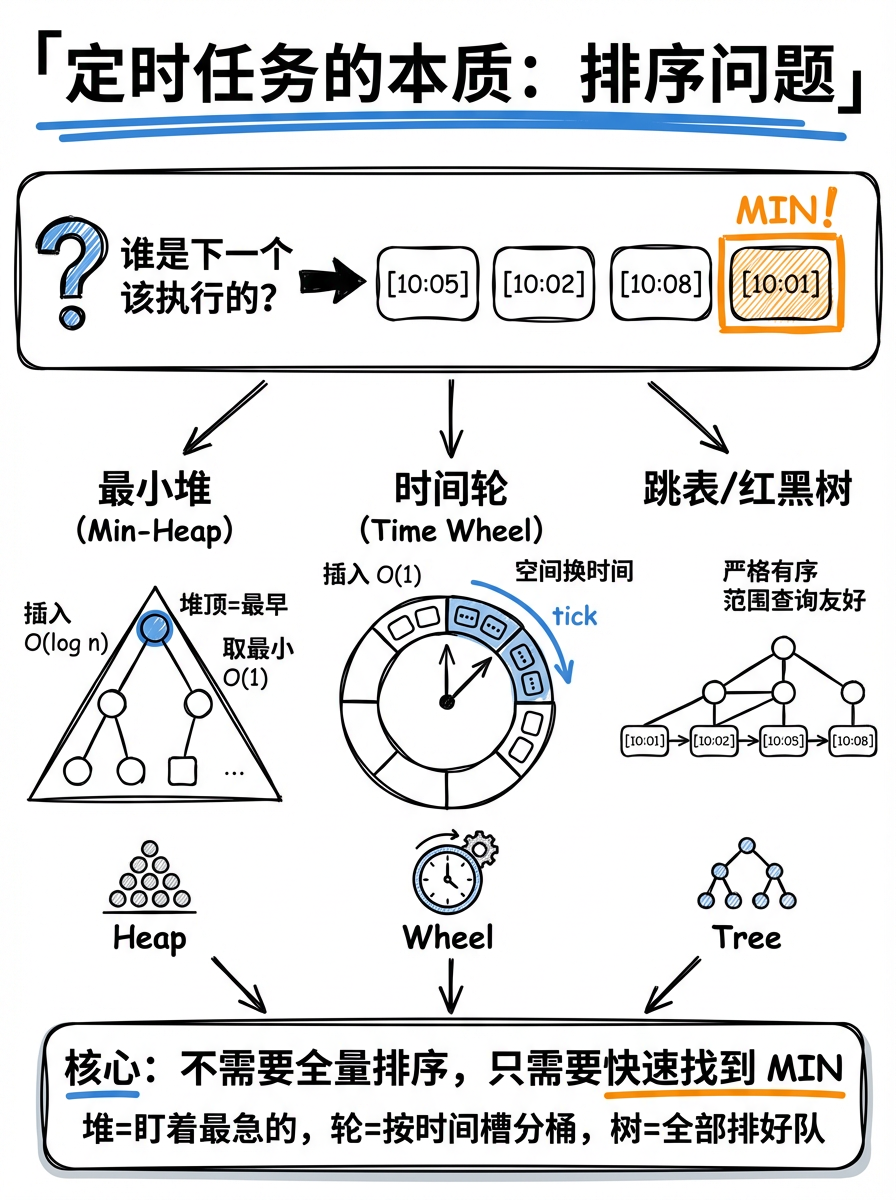
> 定时任务的本质是按“执行时间戳”进行排序。
> 这些数据结构(堆、时间轮、平衡树)其实都是在不同维度上折中处理“排序”的成本,以达到在高并发下依然能准时触发的效果。
>
## 浏览器的定时任务
定时同步配置:
- 首次延迟:1 分钟后触发
- 周期:每 5 分钟同步一次
- 使用 chrome.alarms API(MV3 兼容)
改动:
1. background.js - 添加 chrome.alarms 定时器
2. manifest.json - 添加 alarms 权限
## macOS 的定时任务
___
你观察得很敏锐。**定时任务的本质确实是一个排序(Sorting)与检索(Retrieval)的问题**,更准确地说,是一个**“动态维护最小值的排序问题”**。
在定时任务系统中,我们并不关心所有任务的顺序,我们只关心**“哪一个任务是下一个该执行的”**。
以下是为什么需要这些特定数据结构的深度解析:
---
## 1. 核心矛盾:效率与精度的平衡
定时任务有两个关键操作:
- **插入(Add)**:随时可能新增一个 5 分钟后执行的任务。
- **扫描/执行(Tick/Execute)**:系统需要知道现在谁该出场了。
如果用简单的**无序列表**,插入很快 $O(1)$,但每次“寻找谁该执行”都要全表扫描 $O(n)$,任务多了 CPU 就会不堪重负。
---
## 2. 为什么是这些数据结构?
### **最小堆 (Min-Heap)**
堆是处理定时任务最经典的数据结构(比如 Go 的 `timer`,Java 的 `PriorityQueue`)。
- **本质**:它只保证根节点是最小的(即最早到期的任务)。
- **优势**:
- **获取最小值**:$O(1)$。
- **插入与删除**:$O(\log n)$。
- **逻辑**:系统只需要盯着堆顶。如果堆顶任务还没到时间,系统就可以放心地 `sleep` 到那个时间点,而不需要空转。
### **时间轮 (Hierarchical Wheel)**
如果你看过你图片里的内容,可能包含类似 Netty 或 Kafka 使用的时间轮。
- **本质**:它将排序问题转化为了**空间换时间**的桶算法。
- **优势**:插入、删除、执行的平均时间复杂度都是 **$O(1)$**。
- **逻辑**:它像一个真实的钟表,指针每秒移动一格。落在当前格子的任务直接执行。它不需要像堆那样进行频繁的比较和调整,非常适合任务量极大的场景。
### **跳表 (Skip List) / 红黑树 (Red-Black Tree)**
在 Redis 的 `zset`(延迟队列常用)或 Linux 内核调度中常见。
- **本质**:维持一个**严格有序**的序列。
- **优势**:除了能快速找到最小值,还能方便地进行**范围查询**(比如:找出所有在 10:00 到 10:05 之间过期的任务)。
---
## 3. 总结:为什么说是排序?
定时任务的本质是**按“执行时间戳”进行排序**。
1. **静态排序是不够的**:因为任务是动态增加、取消的。
2. **全量排序是浪费的**:我们不需要知道后天执行的任务谁先谁后,我们只需要知道**眼下**谁最急。
所以,这些数据结构(堆、时间轮、平衡树)其实都是在**不同维度上折中处理“排序”的成本**,以达到在高并发下依然能准时触发的效果。
---
你目前是在研究特定的定时任务框架(如 Quartz 或 XXL-JOB)的源码实现,还是在为你的 Mac 应用 **“语界” (Welt)** 设计后台逻辑?我可以根据你的具体场景推荐更适合的方案。
# 🧩 Cues
# 🪞Notes
# 定时任务核心原理详解
## **Timer实现原理**
```java
public class Timer {
// 任务队列(最小堆)
private final TaskQueue queue = new TaskQueue();
// 工作线程
private final TimerThread thread = new TimerThread(queue);
class TimerThread extends Thread {
public void run() {
while (true) {
TimerTask task = queue.getMin();
long currentTime = System.currentTimeMillis();
if (task.nextExecutionTime <= currentTime) {
// 执行任务
task.run();
// 重新计算下次执行时间
queue.rescheduleMin(period);
} else {
// 等待到下次执行时间
wait(task.nextExecutionTime - currentTime);
}
}
}
}
}
```
## **ScheduledThreadPoolExecutor原理**
```java
public class ScheduledThreadPoolExecutor {
// 延迟队列存储任务
private final DelayedWorkQueue workQueue;
class DelayedWorkQueue extends AbstractQueue<Runnable> {
// 小顶堆数组
private RunnableScheduledFuture<?>[] queue;
// 堆排序保证最早执行的任务在堆顶
private void siftUp(int k, RunnableScheduledFuture<?> key) {
while (k > 0) {
int parent = (k - 1) >>> 1;
if (key.compareTo(queue[parent]) >= 0)
break;
queue[k] = queue[parent];
k = parent;
}
queue[k] = key;
}
}
}
```
## **时间轮(Timing Wheel)算法**
```java
public class TimingWheel {
// 环形数组
private final List<Bucket>[] wheel;
// 时间精度
private final long tickMs;
// 当前指针
private long currentTime;
// 添加任务
public void addTask(TimerTask task) {
long delay = task.delayMs;
// 计算槽位
int index = (int)((currentTime + delay) / tickMs % wheel.length);
wheel[index].add(task);
}
// 推进时间
public void advanceClock(long timeMs) {
if (timeMs >= currentTime + tickMs) {
currentTime = timeMs - (timeMs % tickMs);
// 处理当前槽位的任务
int index = (int)(currentTime / tickMs % wheel.length);
Bucket bucket = wheel[index];
bucket.flush(); // 执行到期任务
}
}
}
```
### **多层时间轮**
```Java
第一层:秒级(60个槽)
第二层:分钟级(60个槽)
第三层:小时级(24个槽)
任务降级:
小时轮 → 分钟轮 → 秒轮 → 执行
```
## **XXL-JOB架构**
```Java
调度中心(xxl-job-admin)
├── 任务管理
├── 调度线程池
├── 触发器(Trigger)
└── 路由策略
执行器(xxl-job-executor)
├── 任务处理器(JobHandler)
├── 执行线程池
├── 日志处理
└── 回调服务
通信方式
├── HTTP/RPC调用
└── 心跳检测
```
## **XXL-JOB分片原理**
```java
// 执行器获取分片参数
int shardIndex = XxlJobContext.getXxlJobContext().getShardIndex();
int shardTotal = XxlJobContext.getXxlJobContext().getShardTotal();
// 业务处理示例
List<User> userList = userService.getAllUsers();
for (User user : userList) {
// 分片处理:当前执行器只处理属于自己分片的数据
if (user.getId() % shardTotal == shardIndex) {
processUser(user);
}
}
```
## **常见定时任务方案对比**
| 方案 | 优点 | 缺点 | 适用场景 |
| :------------------ | :---------------- | :--------------------- | :--------------- |
| **Timer** | 简单轻量 | 单线程、异常处理差 | 简单场景 |
| **ScheduledExecutor** | 线程池、异常隔离 | 单机、不支持持久化 | 中小型应用 |
| **Spring @Scheduled** | 注解方便、集成好 | 单机、不支持动态 | Spring应用 |
| **Quartz** | 功能强大、支持集群 | 配置复杂、性能一般 | 企业级应用 |
| **XXL-JOB** | 分布式、可视化、分片 | 需要部署调度中心 | 分布式系统 |
| **Elastic-Job** | 分布式、弹性扩容 | 依赖ZK、停止维护 | 大规模分布式 |
## **定时任务设计要点**
### **1. 防止重复执行**
```java
// 分布式锁方案
@Scheduled(cron = "0 0 2 * * ?")
public void task() {
String lockKey = "task_lock_" + DateUtil.today();
if (redisLock.tryLock(lockKey, 3600)) {
try {
// 执行任务
doTask();
} finally {
redisLock.unlock(lockKey);
}
}
}
```
### **2. 任务补偿机制**
```java
// 扫描补偿
@Scheduled(fixedDelay = 60000)
public void compensate() {
// 查询失败或超时的任务
List<Task> failedTasks = taskService.findFailedTasks();
for (Task task : failedTasks) {
// 重试执行
retryExecute(task);
}
}
```
### **3. 优雅关闭**
```java
@PreDestroy
public void shutdown() {
// 等待当前任务完成
scheduler.shutdown();
try {
if (!scheduler.awaitTermination(60, TimeUnit.SECONDS)) {
scheduler.shutdownNow();
}
} catch (InterruptedException e) {
scheduler.shutdownNow();
}
}
```
## **高性能定时任务设计**
### **分层架构**
```Java
触发层:负责任务触发
├── 时间轮(高性能)
├── 优先队列(精确调度)
└── Cron解析器
调度层:负责任务分发
├── 负载均衡
├── 失败重试
└── 限流控制
执行层:负责任务执行
├── 线程池
├── 异步处理
└── 结果回调
```
### **数据结构选择**
| 数据结构 | 时间复杂度 | 优点 | 缺点 |
| :------- | :--------- | :------- | :--------- |
| **最小堆** | $O(\log N)$ | 精确、简单 | 大量任务性能差 |
| **时间轮** | $O(1)$ | 高性能 | 精度受限 |
| **红黑树** | $O(\log N)$ | 平衡、稳定 | 实现复杂 |
| **跳表** | $O(\log N)$ | 简单、并发好 | 空间占用大 |
## **最佳实践**
1. **任务幂等**:保证重复执行不影响结果
2. **超时控制**:设置合理的执行超时时间
3. **监控告警**:任务执行状态监控
4. **错误处理**:失败重试和补偿机制
5. **资源隔离**:不同优先级任务分离
6. **日志记录**:完整的执行日志
7. **动态调整**:支持运行时修改配置
## 长耗时任务的解决方案
| 方案 | 适用场景 | 复杂度 |
| :------------------------ | :--------------- | :----- |
| 增大 timeout_milliseconds | <60s 的任务 | 低 |
| Edge Function 内拆分批次 | 数据量大但单步快 | 中 |
| 异步队列模式 | 真正的长任务(分钟级) | 中高 |
异步队列模式的思路:
cron → Edge Function(秒级)
↓
往 job_queue 表写一条 pending 记录,立即返回 200
↓
另一个 cron 每分钟轮询 job_queue
↓
取出 pending 任务,分步执行
不过目前你的场景(调 AI API + 写 Notion)实测 10-20 秒就完成了,60 秒绰绰有余。等真遇到更复杂的任务再升级架构也不迟。