# Summary
## 一、机器学习就两种
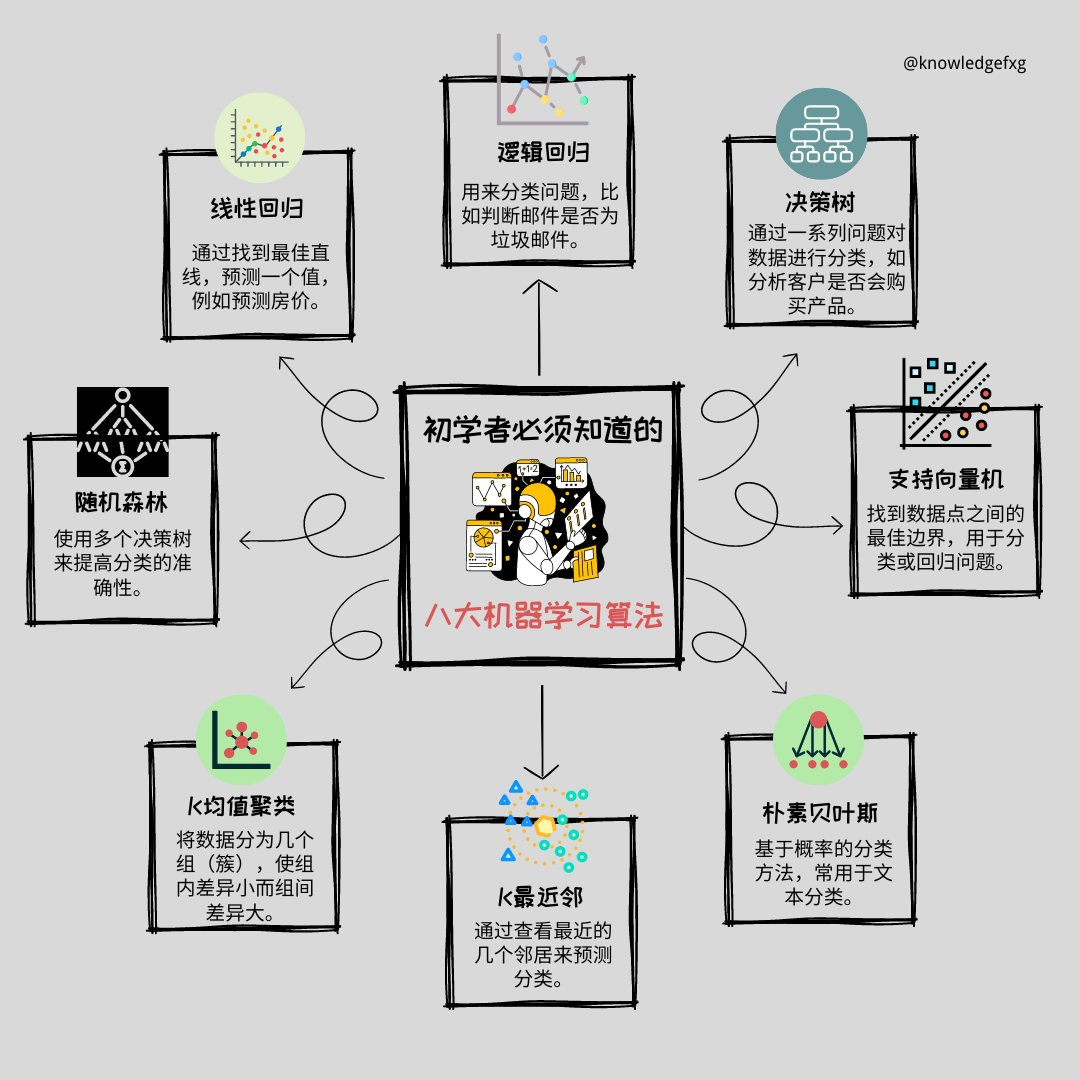
1. [[传统机器学习]],([[逻辑回归LR]]、随机森林、[[支持向量机 SVM]]等)
2. 用[[神经网络]]的[[深度学习@]]。
3. [[强化学习(Reinforcement Learning)]]
## 二、完整过程
| | 过程 | 关键概念 |
| --- | ------------------- | --------------------------------------------------------- |
| 1 | [[数据探索 EDA]] | |
| 2 | [[特征工程]] | |
| 3 | [[数据清洗]] | |
| 4 | 数据划分 [[K折交叉验证]] | [[训练集]](70%)、[[验证集]](15%)和[[测试集]](15%) |
| 5 | 模型训练 | 1. [[损失函数]]、[[交叉熵 cross_entropy]]<br>2. [[优化器 optimizer]] |
| 6 | [[超参数]]调优 | |
| 7 | [[模型评估]] | |
| 8 | [[可解释性分析]] | |
## 三、体感
目前机器学习最能打的算法是什么?- 周晟的回答 - 知乎
https://www.zhihu.com/question/403423969/answer/1983874910
# Cues
[[深度学习@]]
# Notes
```Java
机器学习算法
├── 模型(What)- 要学什么
│ ├── 线性模型
│ ├── 树模型
│ └── 神经网络
│
├── 损失函数(How Good)- 怎么衡量好坏
│ ├── MSE(回归)
│ ├── 交叉熵(分类)
│ └── 自定义损失
│
└── 优化算法(How)- 怎么找到最好的
├── 梯度下降 ← 在这个层次!
├── 遗传算法
└── 贝叶斯优化
```
```Java
output_folder/
│
├── Data/
│ ├── train/
│ ├── test/
│ └── validation/
│
├── main.py
├── model.py
├── utils.py
├── train.py
├── test.py
└── test_notebook.ipynb
```
## 一、不同学习范式
| 类型 | 主要特点 | 学习方式 | 典型算法/模型 |
| ------------------------------------ | ------------- | -------------- | ------------------------------------------------------- |
| [[监督学习]] | 有标签数据训练,预测结果 | 通过标注数据学习映射关系 | [[线性回归]]、[逻辑回归LR](逻辑回归LR.md)、<br>[[决策树]]、[[支持向量机 SVM]]、KNN、|
| [[无监督学习 (Unsupervised Learning)]] | 无标签数据,发现数据特征 | 从数据中自动发现模式 | [[K-means]]、层次聚类、[[PCA]]、自编码器 |
| [[半监督学习 (Semi-Supervised Learning)]] | 结合有标签和无标签数据 | 利用少量标注和大量未标注数据 | 标签传播、自训练、协同训练 |
| [[强化学习(Reinforcement Learning)]] | 通过与环境交互学习策略 | 基于奖励和惩罚的试错学习 | Q-learning、SARSA、策略梯度、DQN |
| 迁移学习 | 将已学知识迁移到新任务 | 利用源域知识优化目标域学习 | 预训练模型微调、领域自适应 |
| [[集成学习]] | 组合多个基学习器 | 通过模型组合提高性能 | Bagging、[[随机森林]]、Boosting、[[XGboost]] |
| [[深度学习@]] | 多层神经网络,自动特征学习 | 端到端的特征学习和任务学习 | CNN、RNN、Transformer、GAN |
| | | | |
## 二、数学基础
做好机器学习,数学要学到什么程度?- 人民邮电出版社的回答 - 知乎
https://www.zhihu.com/question/68472622/answer/1781641922
| 类别 | 算法 | 所用的数学知识 |
|:-------- |:------------------- |:---------------------------------------------------------------- |
| **分类与回归** | [[贝叶斯分类]]器 | 随机变量, [[贝叶斯公式]] [[正态分布 高斯分布]], [[最大似然估计]] |
| | 决策树 | [[信息熵]], [[信息增益]], Gini系数 |
| | KNN算法 | 距离函数 |
| | 线性判别分析 | 散度矩阵, 逆矩阵, 瑞利商, 拉格朗日乘数法, 特征值与特征向量, 标准正交基 |
| | 神经网络 | 矩阵运算, 链式法则, 交叉熵, 欧氏距离, 梯度下降法 |
| | 支持向量机 | 点到超平面的距离, 拉格朗日对偶, 强对偶, Slater条件, KKT条件, 凸优化, 核函数, Mercer条件, SMO算法 |
| | logistic回归与softmax回归 | 条件概率, 伯努利分布, 多项分布, 最大似然估计, 凸优化, 梯度下降法, 牛顿法 |
| | 随机森林 | 抽样, 方差 |
| | Boosting算法 | 牛顿法, 泰勒公式 |
| | 线性回归, 岭回归, LASSO回归 | 均方误差, 最小二乘法, 向量范数, 梯度下降法, 凸优化 |
| **数据降维** | 主成分分析 | 均方误差, 协方差矩阵, 拉格朗日乘数法, 特征值与特征向量, 标准正交基 |
| | 核主成分分析 | 核函数 |
| | 流形学习 | 线性组合, 均方误差, 相似度图, 拉普拉斯矩阵, 特征值与特征向量, 拉格朗日乘数法, KL散度, t分布, 测地距离 |
| | | |
| | | |
| 类别 | 算法 | 所用的数学知识 |
|:---------------- |:-------------------- |:---------------------------------------------------------------------------------------------------- |
| **距离度量学习** | NCA | 概率, 梯度下降法 |
| | ITML | KL散度, 带约束的优化 |
| | LMNN | 线性变换, 梯度下降法 |
| **概率图模型** | 高斯混合模型与EM算法 | 正态分布, 多项分布, 边缘分布, 条件分布, 数学期望, Jensen不等式, 凸函数, 最大似然估计, 拉格朗日乘数法 |
| | 高斯过程回归 | 正态分布, 条件分布 |
| | HMM | 马尔可夫过程, 条件分布, 边缘分布, 最大似然估计, EM算法, 拉格朗日乘数法 |
| | CRF | 图, 条件概率, 最大似然估计, 拟牛顿法 |
| | 贝叶斯网络 | 图, 条件概率, 贝叶斯公式, 最大似然估计 |
| **聚类** | K均值算法 | EM算法 |
| | 谱聚类 | 图, 拉普拉斯矩阵, 特征值与特征向量 |
| | Mean Shift算法 | 核密度估计, 梯度下降法 |
| **深度生成模型** | GAN | 概率分布变换, KL散度, JS散度, 互信息, 梯度下降法 |
| | VAE | 概率分布变换, KL散度, 变分推断, 梯度下降法 |
| | 变分推断 | KL散度, 变分法, 贝叶斯公式 |
| | MCMC采样 | 马尔可夫链, 平稳分布, 细致平衡条件, 条件概率 |
| | | |
| | | |
## 三、任务类型
除分类和回归外,机器学习的任务类型还包括聚类、降维、生成式建模、异常检测、强化学习、推荐与排序、度量学习以及各种决策与控制任务等。
不同任务类型与不同学习范式(有监督、无监督、半监督、强化学习)相结合,构成了机器学习广阔的应用和研究领域。
| 学习范式 / 任务类型 | 描述与示例 |
|:----------------------------------- |:---------------------------------------------------------------------------------------------------------- |
| [[无监督学习 (Unsupervised Learning)]] | [[聚类 (Clustering)]]:将没有标签的数据根据其内在特征和分布分成不同组别,如K-Means、DBSCAN。|
| | 密度估计 (Density Estimation):为数据学习一个概率分布模型,从而评估数据点的可能性或异常性。|
| | 降维/[[表征学习]] (Dimensionality Reduction / Representation Learning):将高维数据映射到低维空间,以保留尽可能多的信息并便于后续分析,如PCA、t-SNE。|
| [[半监督学习 (Semi-Supervised Learning)]] | 当只有少量有标签数据和大量无标签数据时,模型可利用无标签数据结构和分布信息提高有标签数据的分类或回归效果。|
| [[强化学习 (Reinforcement Learning)]] | 代理(agent)通过与环境交互获得奖励或惩罚,不断学习策略(policy)以最大化长期回报。例如,游戏中的智能体决策、机器人动作规划。|
| [[生成式学习 (Generative Modeling)]] | 学习数据分布以生成与原数据相似的样本。该类任务不以预测标签为目的,而是侧重于"创造"与原数据统计特性相似的新样本。|
| | 生成对抗网络 (GAN):生成逼真的图像、语音或文本。|
| | 变分自编码器 (VAE):通过概率图模型生成新样本。|
| 序列预测与时序分析 | 针对时间序列或序列数据的学习与预测,如下一个时间点的数值预测、机器翻译中预测下一词、语音识别、文本生成等。|
| 异常检测 (Anomaly / Outlier Detection) | 识别与正常数据模式偏差较大的异常点,用于入侵检测、故障检测、欺诈发现等。|
| [[推荐算法]] | 基于用户历史行为或偏好,利用协同过滤或内容过滤等方法,为用户推荐商品、服务或内容。|
| 度量学习 (Metric Learning) | 学习适合特定任务的距离或相似度度量,以便在后续任务中根据相似度进行检索或匹配。|
| 排序 (Ranking) | 对对象集合进行排序,如搜索引擎的搜索结果排序、新闻与文章的推送排序。|
| 策略优化和控制 (Control Tasks) | 类似强化学习,与决策控制相关,包括自动驾驶中的轨迹规划、机器人手臂抓取物体的控制策略优化。|
| 章节 | 标题 | 主要内容 |
| ---- | -------------------------------- | ------------------------------------------------------ |
| 第1章 | 绪论 | 1.1 基本术语, 1.2 假设空间, 1.3 归纳偏好, 1.4 发展历程 |
| 第2章 | 模型评估与选择 | 2.1 误差与过拟合, 2.2 评估方法, 2.3 性能度量, 2.4 偏差与方差 |
| 第3章 | 线性模型 | 3.1 线性回归, 3.2 线性判别分析, 3.3 [逻辑回归LR](逻辑回归LR.md), 3.4 感知机 |
| 第4章 | [[决策树]] | 4.1 基本算法, 4.2 适应连续值, 4.3 生成对抗剪枝, 4.4 其他问题 |
| 第5章 | [[神经网络]] | 5.1 单层网络, 5.2 多层前馈网络, 5.3 [[反向传播]], 5.4 [[深度学习@]]简介 |
| 第6章 | [[支持向量机 SVM]] | 6.1 间隔与支持向量, 6.2 线性可分支持向量机, 6.3 软间隔支持向量机, 6.4 非线性支持向量机 |
| 第7章 | [[贝叶斯分类]] | 7.1 生成学习与判别学习, 7.2 朴素贝叶斯法, 7.3 贝叶斯网络, 7.4 最大后验概率估计 |
| 第8章 | 集成学习 | 8.1 基本方法, 8.2 Bagging, 8.3 Boosting, 8.4 随机森林 |
| 第9章 | 聚类方法 | 9.1 原型聚类, 9.2 密度聚类, 9.3 层次聚类, 9.4 混合聚类 |
| 第10章 | 降维与度量学习 | 10.1 线性判别分析, 10.2 [[主成分分析]], 10.3 流形学习, 10.4 度量学习 |
| 第11章 | 特征选择与稀疏学习 | 11.1 过滤法, 11.2 包装法, 11.3 嵌入法, 11.4 稀疏表示 |
| 第12章 | 计算学习理论 | 12.1 [[PAC 学习]], 12.2 [[VC 维]], 12.3 泛化界, 12.4 统计学习理论 |
| 第13章 | [[强化学习(Reinforcement Learning)]] | 13.1 强化学习基础, 13.2 马尔可夫决策过程, 13.3 价值迭代与策略迭代, 13.4 Q 学习 |
| 附录 | - | A.1 数学基础, A.2 相关数据集 |