# Summary
**重排序是用一个「新模型」重新计算 query 和 doc 的相关性分数**
## 一、原理
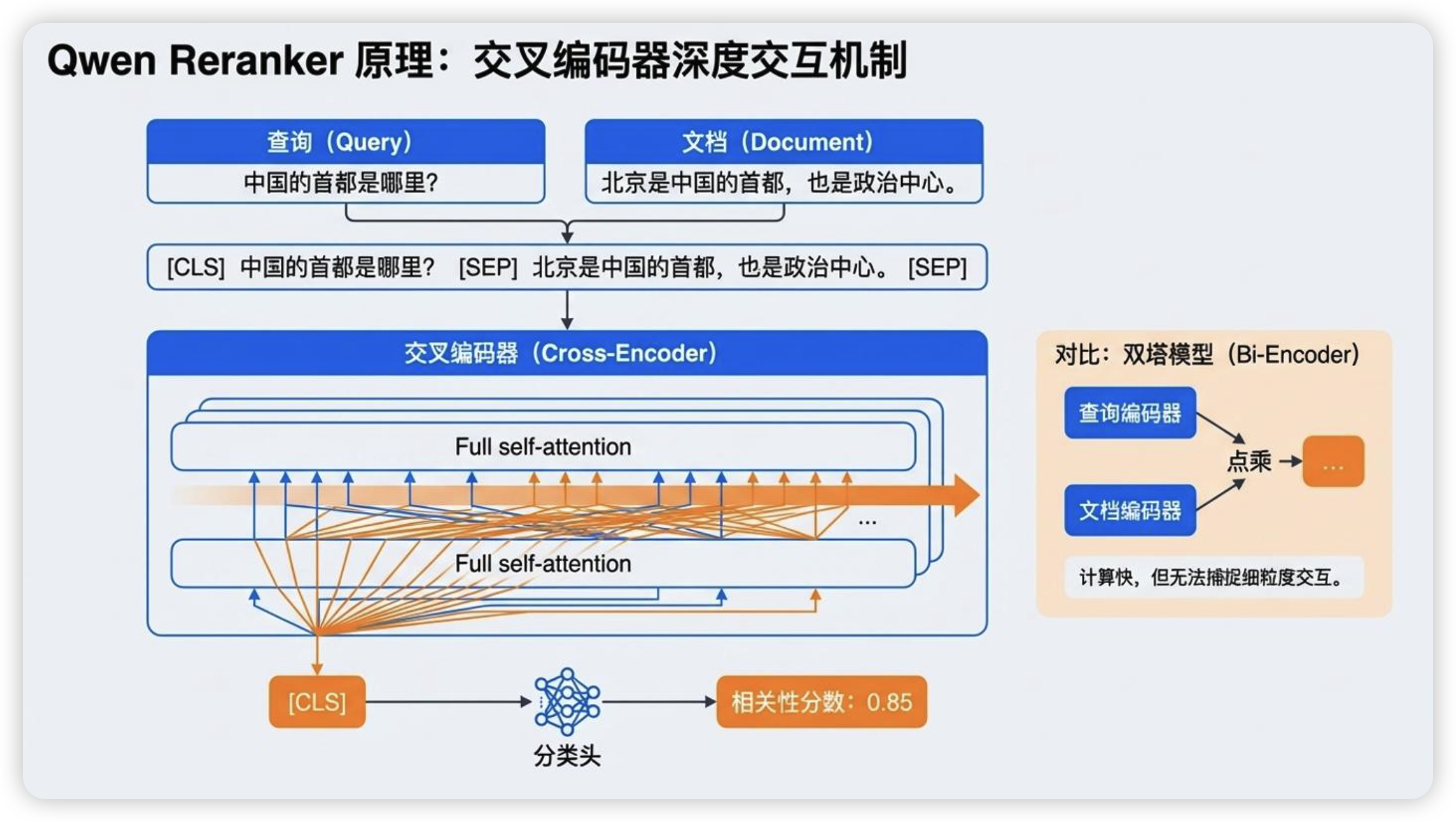
```python
# 拼接后一起编码
input_text = "[CLS] query [SEP] doc [SEP]"
score = reranker(input_text) # 直接输出相关性分数
# 优点:query 和 doc 充分交互,精度更高
# 缺点:必须在线计算,慢(只能处理几十到几百个候选)
```
## 二、在搜索中的位置
```
用户查询
↓
召回阶段: 向量搜索/BM25 → 候选 Top100
↓
重排阶段: Qwen Rerank → 精排 Top10
↓
生成阶段: 送入 LLM 生成答案
```
## 三、适用
**适合用 Rerank 的场景:**
- 召回结果质量参差不齐
- 需要高精度(如法律、医疗问答)
- 查询意图复杂
**不适合的场景:**
- 延迟要求极高(< 100ms)
- 候选文档数量巨大(> 1000)
- 简单的关键词匹配就够了
## 四、Reranker 模型对比
|模型|语言|参数量|特点|
|---|---|---|---|
|**Qwen Rerank**|中英|1.5B/7B|中文效果好,上下文长|
|**BGE Reranker**|中英|多种规格|智源出品,开源社区常用|
|**Cohere Rerank**|多语言|未公开|商业API,效果强但收费|
# Cues
[[混合搜索、粗召回(粗排)]]
# Notes
## 一、与双塔模型(Bi-Encoder)的区别
**双塔模型(用于召回)**:
```python
# 分别编码,可以离线计算
query_vector = encoder(query) # [1, 768]
doc_vector = encoder(doc) # [1, 768]
score = cosine_similarity(query_vector, doc_vector) # 点积
# 优点:速度快,支持百万级检索
# 缺点:query 和 doc 独立编码,交互不足
```
**Cross-Encoder(用于重排序)**:
```python
# 拼接后一起编码
input_text = "[CLS] query [SEP] doc [SEP]"
score = reranker(input_text) # 直接输出相关性分数
# 优点:query 和 doc 充分交互,精度更高
# 缺点:必须在线计算,慢(只能处理几十到几百个候选)
```
## 二、CLS 和 SEP 是什么?
这是 **BERT 类模型的特殊标记符号**,可以把它们理解为"标点符号",帮助模型理解文本结构:
**`[CLS]`** - Classification Token (分类标记),> 就像看一篇文章,标题写着"[总结]",你知道这里会给出整体结论
- **位置**: 永远放在**最开头**
- **作用**: 像一个"总结者",模型会把整段文本的**综合信息**都汇聚到这里
- **输出**: Reranker 最后就看这个位置的输出来判断相关性分数
**`[SEP]`** - Separator Token (分隔符) > 就像聊天时用 "---" 分隔不同话题
- **位置**: 放在**不同部分之间**
- **作用**: 告诉模型"这是两个不同的东西,别混淆"
- **类似**: 中文的顿号、分号
---
## 实际例子
假设你搜索 **"北京天气"**,候选文档是 **"今天北京多云转晴"**
```python
# Reranker 实际看到的输入:
"[CLS] 北京天气 [SEP] 今天北京多云转晴 [SEP]"
# 模型内部处理:
# 1. [CLS] 的位置会综合理解整个句子
# 2. [SEP] 告诉模型: 前面是query,后面是文档
# 3. 最后输出 [CLS] 位置的分数 → 比如 0.92 (很相关!)
```
---
## 为什么需要这些标记?
|场景|不用标记|用了标记|
|---|---|---|
|**区分部分**|"北京天气今天北京多云" <br> 😵 模型分不清哪是query|"[CLS]北京天气[SEP]今天..." <br> ✅ 清楚知道结构|
|**获取分数**|不知道看哪个位置的输出|直接看[CLS]的输出|
---
## 核心要点
- `[CLS]` = 开头的"总结位置",输出最终分数
- `[SEP]` = 中间的"分隔符",区分 query 和 doc
- 这是 BERT 训练时就定好的**约定俗成**,就像 HTTP 协议里的 `GET`、`POST` 一样
___
你碰到的是经典的 “交叉编码器(cross-encoder)用于排序 / Learning-to-Rank 的训练数据构造” 的变体——也就是用 BERT(query, doc) 联合建模并输出打分的那一类监督学习问题。
下面我把能直接用、样式清晰的训练数据格式、常见标签策略、负样本采样、损失函数与工程实践要点都列出来——并给出具体的 JSON/伪码样例,方便你直接落地。
一、常见的数据格式(3 种主流)
1. Pointwise(点式)
每条样本是一个 (query, doc, label),label 是标量(binary/graded/score)。
示例(JSONL):
```
{"query":"如何做披萨?","doc":"披萨做法:先准备面团...","label":1}
{"query":"如何做披萨?","doc":"苹果派的做法:先...","label":0}
```
训练时用回归或分类损失(如二分类交叉熵或 MSE / regression loss)。
2. Pairwise(对式 / 三元组)
每条是 (query, positive_doc, negative_doc) 或 (query, pos, negs[]),目标是 score(q,pos) > score(q,neg)。
示例:
```
{"query":"python 列表去重","positive":"使用 set 去重的示例代码...", "negative":"如何写一个 C++ 类?"}
```
常用损失:hinge loss、pairwise cross-entropy(BPR)等。
3. Listwise(序列式 / 多候选)
每条是 (query, candidates=[{doc,label}, ...]),标签可以是 0/1 或 0/1/2/3(分级)。训练时把同一 query 的所有候选一起做 softmax + cross-entropy(更直接优化排序指标)。
示例:
```
{"query":"南京旅游必去","candidates":[
{"doc":"中山陵介绍...", "label":2},
{"doc":"附近的餐馆列表...", "label":1},
{"doc":"股票行情今天...", "label":0}
]}
```
二、标签类型(怎么标注)
• Binary(0/1):相关 / 不相关。标注简单,常用在 QA、FAQ 场景。
• Graded(0..3/4):不相关 / 低相关 / 中等 / 高相关。对排序更细腻,有助于 listwise loss。
• Soft labels(概率/分数):来自自动模型(如 cross-encoder 给出的分数)或多个标注者的平均分,用于蒸馏训练。
三、负样本(非常关键)
• 随机负(Random):简单但效果有限。
• in-batch negatives:把 batch 内其他 doc 当负样本,训练效率高。
• hard negatives(困难负样本):用 BM25 / 现有 bi-encoder / heuristic 筛出的高相似但不相关的 doc,训练效果大提升。
• 动态挖掘:训练中周期性用当前模型检索再更新负样本(在线挖掘)。
四、输入格式与截断(工程细节)
• 把 query 和 doc 拼接:[CLS] query [SEP] doc [SEP](或使用 tokenizer 的 encode_plus(query, doc))。
• 截断策略:通常把 max_length 分配给 doc(truncation='only_second'),保证 query 完整。
• 可以加入额外特征(点击次数、bm25 score)作为额外的输入 head,但大多数情况下先用文本本身即可。
五、常用损失及训练策略
• Pointwise:binary CE 或回归 MSE。
• Pairwise:hinge loss max(0, margin - s(pos)+s(neg)) 或 pairwise CE(BPR)。
• Listwise:softmax over candidates(给每个候选计算 exp(s)/sum(exp(s)))然后用 cross-entropy 使 ground-truth 在分布中概率最高——这个在多候选、同 query batch 非常好用。
• In-batch softmax / InfoNCE:把整个 batch 的所有 docs 作为 negatives,常用于对比学习与蒸馏。
六、具体样例(二种常见训练数据 JSONL)
七、训练时的具体实现思路(伪码)
`loss = F.cross_entropy(scores, labels)`
八、数据规模与标注成本建议
• 小规模实验:每个 query 10~100 个候选、上万条 query(数万—十万样本)可见明显效果。
• 生产级:十万—百万级 query + 每 query 多个候选,且结合自动挖掘的 hard negatives。
• 标注:优先做高质量的正例 / hard negatives;多个标注者交叉检查以减少噪声。
九、常见实践与技巧
1. 先用 bi-encoder+ANN 做召回,再在召回 top-K 上做 cross-encoder 精排(训练 cross-encoder 用上面 listwise/pairwise 数据)。
2. 训练数据来源:用户点击/点击-未点击信号(implicit feedback)、人工标注(explicit relevance)、现有交叉模型的打分(蒸馏软标签)。
3. 蒸馏:用强 cross-encoder 给 bi-encoder 生成软标签,或用 cross 的分数作为训练目标提升 bi-encoder。
4. 评估:在 dev 上用 Recall@K、MRR、NDCG、以及 downstream RAG 的生成质量一并评估。
5. 样本平衡:注意绝大多数负样本会导致训练不稳定,使用 in-batch + hard negatives 更稳妥。
6. 标签噪声处理:对人标结果做一致性校验,或给每条样本加权(more confident sample weight)。
十、我可以直接给你的东西(你选一项我马上给)
• A. 可运行的数据生成 + HuggingFace transformers 脚本(从 JSONL 到 DataLoader,再到训练 loop,含 listwise softmax 示例)。
• B. 标注指引模板(用于告诉标注员如何标注 0/1/2/3、示例与边界情况)。
• C. 负样本挖掘与 hard negative mining 的实现示例(BM25 + bi-encoder 混合采样脚本)。