# Summary
[[隐马尔科夫过程]]
其实从gpt4大火至今,我们一直都在焦虑,会不会有新模型、新架构把之前的工作全部推翻呢?事实上并没有,Ir、[[deepfm]]仍然是短平快的首选,多目标就上[[mmoe]]+,谈序列就上[[DIN]] ……都是人尽皆知的老模型,至少我们的业务是,多加点注意力机制都要老命了 召回模型还是双塔+及其变种,但数据量少的业务双塔都搭不起来;itemcf、swing、eges仍然是不可或缺的主力,剩下的就是各种策略召回⋯⋯ 那我们搞推荐的最近究竟在干嘛呢?1. 研究怎么与大模型结合,不仅是技术上的结合(比如让ds成本低速度快的新技术),更是业务上的结合(比如新的交互形式)2.超长序列模型,这是偏技术探索的方向,“不做特征工程,纯靠用户历史行为”,听起来很理想,所以我们也在等待一个工业界成功的案例 3.更加实时化,这是偏工程的方向,无论是策略、模型、数据,实时化都能拿到收益 4.卷embedding,各种多模态信息想办法全塞进去,不想做特征的就去做embedding优化,这相关的模型还是挺多的,因为偏离线任务,可做空间也大 5. 特征工程,做一辈子都做不完,它就像海绵里的水一样,挤挤总还是有收益的 6. 其他与业务强相关的优化,把自己当产品用,光做算法工程师没前途的 7.冷启动,个人认为最难的方向,搞过各种模型策略,但我都不敢说有多少收益
1. LR([[逻辑回归LR]]),别看它简单,简直是推荐系统的“定海神针”。为啥?第一,它快,巨快,训练和预测的速度能让你忘记啥叫”等待”。尤其是在需要处理海量稀疏特征的场景(比如用户ID、商品ID这种动不动就上亿维度的),LR配上好的特征哈希和工程优化,效率高的吓人。第二,它稳,结果的可解释性强到离谱。哪个特征权重高,哪个权重低,一目了然。模型出问题了,你回溯debug的时候,思路特别清晰。对于很多金融或者需要强解释性的场景,LR 甚至是唯一选择。第三,它是最强的“参照物”。你搞了个花里胡哨的新模型,AUC涨了0.5个点,别高兴太早,先跟一个精心调过特征的LR比一比,说不定人家把你秒了。
2. LGBM/[[XGboost]],这哥俩是中流砥柱,尤其是LGBM。这玩意儿就是“特征工程”的最好朋友。你灌给它一堆原始的连续、离散特征,它内部能给你自动做切分、组合,发现非线性关系。你辛辛苦苦做的那些交叉特征,LGB可能看一眼就给你拟合出来了。它的强大之处在于,你只要把特征工程做到位,它的效果上限非常非常高。很多时候,一个有着几千维高质量特征的LGB,能跟一个结构一般、特征粗糙的深度模型掰掰手腕,甚至还经常赢。而且它训练快,占资源少,简直是中小公司的福音。
3. [[Wide & Deep]]/ DeepFM,这是从“传统“到”深度“最成功的“立交桥”。Google这篇paper牛就牛在它的思想非常务实。Wide部分(就是个LR)负责”记忆”,把那些”啤酒与尿布”这种强关联的规则给记住;Deep部分(DNN)负责”泛化”,去探索那些你没见过的组合的可能性。这个结构,既有LR的稳,又有DNN的想象力,工程实现也相对简单,效果还出奇的好。所以你看,后面一堆所谓的”新模型”,很多都是在这个框架上修修补补,比如把Wide部分换个花样,或者在Deep部分加点新玩意儿,比如加个 Attention、加个序列啥的。DeepFM更是把FM的二阶交叉思想融入进来,成了现在工业界最最最主流的深度模型baseline。
先把LGB和[[DeepFM]]这两个模型玩得明明白白的,从特征处理、样本选择、模型训练、线上部署到效果评估,把整个链条跑通、吃透。在这个过程中,你遇到的问题,远比你想象的多,解决这些问题的经验,比你看100篇SOTA paper都有价值。当你的baseline 已经做得足够好,业务也确实遇到了瓶颈,需要更强的模型表达能力去突破时,再去研究那些fancy的结构,这时候你才能真正理解它们的价值和局限。
案例二:某内容社区的信息流 这个例子正面一点。我们的基线是DeepFM,已经做得很好了。我们发现用户的“session内兴趣”对点击影响很大,就是用户在一次App会话中,连续刷到的内容是有主题关联的。这时候,你再用复杂的模型就比较“师出有名“了。我们没有完全抛弃DeepFM,而是在它的结构里,加入了一个捕捉短期兴趣的模块。具体来说,就是把用户最近的几次点击的embedding,用一个简单的GRU网络过一下,生成一个代表“短期兴趣“的向量,再拼接到DNN的输入里。这个改动不算巨大,更像是对DeepFM的一次“插件式升级”。它精准地解决了我们发现的业务痛点。最终上线,这个版本比纯DeepFM在人均阅读时长上,稳定提升了1.5%左右。这就是一次非常成功的迭代。你看,关键不在于模型本身有多“新”,而在于你是不是真的理解了业务,你的模型迭代是不是在解决一个真实存在的问题。
# Cues
[[生成式推荐]]
王树森 https://github.com/wangshusen/RecommenderSystem
# Notes
[[MovieLens]]
#最佳实践 短期低估,长期高估
> 一种对算法的常见误会就是:短期高估,长期低估。如果你不是算法工程师,比如产品经理或者运营人员,那么可能你要尤其注意,在一款个性化产品诞生之初,算法所起到的作用可以忽略,我们不能指望它能让产品起死回生、一飞冲天,但就此抛出“算法无用论”也是很愚蠢的。
## 发展历史
| | |
| ------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| 2010年以前 | 推荐系统等于协同过滤,[[协同过滤]]并不是模型 只是一个简单的数学计算罢了,无法捕捉到复杂的规律 |
| 2006 | netflix 的比赛中涌现了矩阵分解。从此进入[[矩阵分解]]的时代。直接让ai画个矩阵示意图 |
| 2016年 | **YouTube DNN论文**发布,标志着深度学习正式进入推荐系统主流。<br>[[Wide & Deep]] 就是这个时代的作品**Wide & Deep**(Google)- 结合记忆和泛化<br>[[DeepFM]](华为)- 自动特征交叉<br>[[DIN]](阿里)- 引入注意力机制<br>[[Transformer]]、BERT等开始应用到推荐系统 |
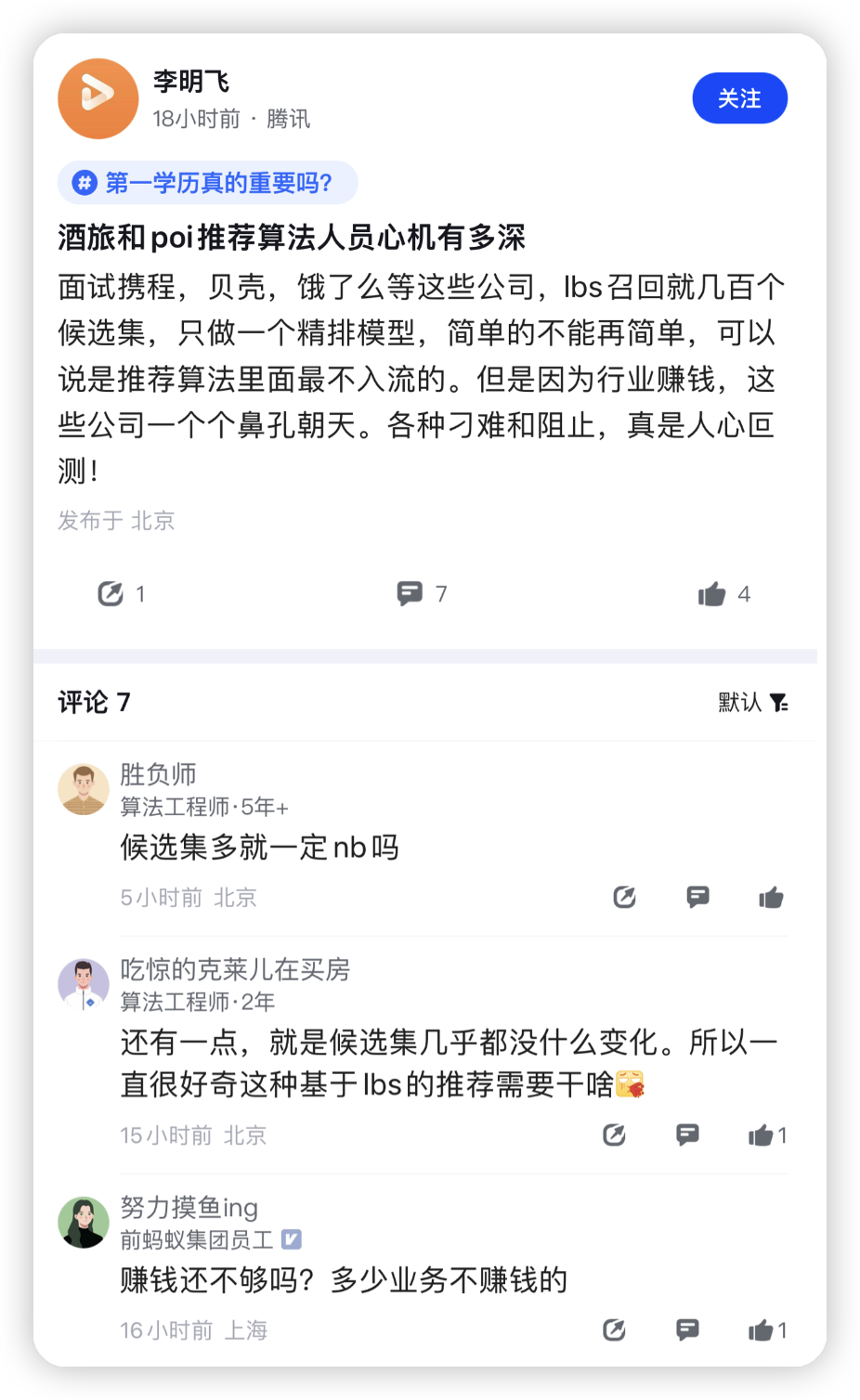
酒旅和poi推荐算法人员心机有多深 面试携程,贝壳,饿了么等这些公司,[[Ibs]]召回就几百个候选集,只做一个精排模型,简单的不能再简单,可以说是推荐算法里面最不入流的。但是因为行业赚钱,这些公司一个个鼻孔朝天。各种刁难和阻止,真是人心回
本人的新书 [资料推荐系统.pdf.zip](https://wiki.corp.qunar.com/download/attachments/758451995/%E8%B5%84%E6%96%99%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F.pdf.zip?version=1&modificationDate=1694655982000&api=v2) 问世一来,反响热烈,广大网友踊跃购买。作为一位拥有多年"被面试"和"面试别人"的互联网老打工人,本人总结了一份互联网大厂推荐算法岗位的经典面试问题清单,以答谢读者。
对于未购买电子书的网友,可以拿这份问题清单测试一下自己的算法水平。如果发现自己在简历上写明使用过某种技术,但是清单中关于这项技术的问题却回答不上来,那就说明你对这个技术的理解还不够深入,还不掌握技术细节,强烈建议你购买 [资料推荐系统.pdf.zip](https://wiki.corp.qunar.com/download/attachments/758451995/%E8%B5%84%E6%96%99%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F.pdf.zip?version=1&modificationDate=1694655982000&api=v2) 恶补一下。
购书方法:_关注微信公众号"石塔西的说书馆",点击"发消息",回复"购书",或点击最下方的"购书"按钮_。
对于已经购买本书的读者,可以拿这份清单测试一下自己的阅读学习成果,是否将本书中的知识都掌握了。建议你将这从清单复制成Word文档,在每道问题下,用最简明扼要的语言写下你的答案。_一定不要抄书,一定要用自己的话来复述,一定要没废话地直击问题核心_,因为在面试的时候,面试官没有时间和耐心等你翻书和长篇大论。本书覆盖了此份清单中大多数问题的答案,但还是有一两道题目,_主观性比较强,没有标准答案,考察的是候选人对推荐系统的经验和理解程度_。
如果对自己的回答没那么大把握,或者对那几道主观题有自己的想法却不知道对错,可以在朋友圈、社群或自己的媒体渠道推荐、转发本文,凭借转发记录就拥有了和作者一对一讨论的机会。也欢迎网友购书入群,分享自己面试或被面试中遇到的好题目,完善本清单。
# 特征工程
- 为什么说,用物料的后验消费数据做召回存在"幸存者偏差"?能将这些消费数据用于排序吗?
- 使用物料的后验消费数据做召回,会放大"马太效应",对新物料不友好,如何缓解?
---
- 解释什么是bias特征?你能举出哪些bias特征的例子?
- bias特征怎样接入模型?能否和其他正常特征一起喂入DNN底层?为什么?
---
- 某男性新用户对"体育"这个分类的喜好程度未知,如何填充?
- 某新物料的后验指标未知,如何填充?
- 对观看次数、观看时长这样的特征,如何做标准化?
- 某个物料曝光2次,被点击1次,如何计算它的CTR?
---
- 有一个特征"某文章过去1天的点击率是10%",如何将其构建成一个类别特征,并喂入推荐模型?
# Embedding
- 为什么说Embedding提升了推荐算法的扩展性?
- FFM针对FM的改进在哪里?
- 简述阿里Co-Action Network的基本思想?
---
- 简述Parameter Server是如何应对推荐系统"高维稀疏"的数据环境的?
- 什么是异步并发(ASP)中的"梯度失效"问题?即使如此,为什么在推荐系统中仍然常用?
# 精排
- FTRL是如何保证"在线学习"的稳定性的?
- FTRL是如何保证解的稀疏性的?
- FTRL是如何解决高维稀疏特征受训机会不均匀的问题的?
---
- FM相对LR的优势在哪里?
- 不能只回答自动交叉
- 是如何解决交叉特征太稀疏、受训机会少的问题的?
- 是如何提高扩展性的?
- FM对所有特征两两交叉,岂不是n方的复杂度?
- 回答是的,这道题直接fail
- 回答不是,要追问FM的实际复杂度是什么?如何实现的?
- FM的缺点有哪些?
- 提示:其中一个缺点是不灵活,怎么理解?
- FFM相对于FM的改进有哪些?为什么要这么改进?
- FFM相比于FM的缺点在哪里?(提示:效率)
---
- Wide & Deep是如何做到兼顾"记忆"与"扩展"的?
- 什么样的特征进Deep侧?什么样的特征进Wide侧?
- Wide & Deep论文原文中说,训练Wide & Deep侧分别使用了两种优化器,你觉得有哪些道理?
---
- DCN解决的是什么问题?
- DCN v1和v2的差别在哪里?
- DCN有哪些缺陷?(提示:输入输出的维度)
---
- 简述基于Transformer做特征交叉的原理?
- Transformer做特征交叉的缺点有哪些?(提示:输入输出维度、时间复杂度)
---
- 你在建模行为序列中的每个元素时,一般会包含哪些信息?如何Embedding?
- 每个用户的行为序列长度不同,如何处理?Truncate很简单,关键是如何解决Padding的问题?
- 不解决的话,两个完全不同的序列,因为被填充的大量的0,而被模型认为相似
- 提示:可以看看TensorFlow Transformer的源码,看看人家是如何解决的?
- Target Attention的时间复杂度
- Self-Attention的时间复杂度
---
- DIN的建模思路是怎样的?怎么理解"千物千面"?
- 每到"双十一"之类的促销季,用户的购买行为与他之前短期行为有较大不同,应该如何建模?
- 其实就是长序列建模的问题,简单套用SIM不是不可以,但是仍然有效率问题
- 开放问题,考察候选人的经验,以及思路是否开阔
- 简述SIM的建模思想?你觉得它的优缺点有哪些?
- 如果想在召回或粗排中建模用户长序列,怎么做?
# 召回
- 传统的协同过滤,User CF和Item CF,哪个在工业界更常用?为什么?
- 大规模、分布式的CF是如何实现的?
- 基于矩阵分解的协同过滤,要分解的矩阵是超级稀疏的,分解这样的矩阵,需要事先将它缺失的地位都填充0吗?
---
- 召回模型中如何处理用户行为序列?
- 回答简单的Pooling的,是常规操作
- 有没有可能也做target attention?拿什么当target?
---
- NCE Loss的基本思想与计算公式
- NEG Loss的基本思想与计算公式?它与NCE Loss是什么关系?
- Marginal Hinge Loss的基本思想与计算公式
- BPR Loss的基本思想与计算公式
---
- Sampled Softmax的基本思想与计算公式
- Sampled Softmax中温度修正的作用?调高温度有什么影响?调低温度有什么影响?
- 采样修正的`Q(t)`应该如何设置?
---
- 从算法机理来阐述热门物料对模型的影响?
- 大家都知道热门物料对推荐结果的个性化造成负面影响,我需要你回答出它是如何造成这一负面影响的
- 为了打压热门物料,热门物料当正样本,应该降采样还是过采样?
- 为了打压热门物料,热门物料当负样本,应该降采样还是过采样?为什么?
---
- Word2Vec中,Skip-Gram和CBOW有什么区别?哪种算法对于罕见词、罕见搭配更友好?
- Airbnb的I2I召回,相比于word2vec,在正样本上有哪些创新?合理性在哪里?
- Airbnb的I2I召回,相比于word2vec,在负样本上有哪些创新?合理性在哪里?
- Airbnb的U2I召回,是如何解决"预订样本"太稀疏这个问题的?
- Airbnb的U2I召回,在负样本上有哪些创新?
- 直接套用Word2Vec用作召回,在正样本的选择上有哪些局限性?
- Airbnb是如何突破这一局限性的?
- 阿里的EGES是如何突破这一局限性的?
---
- 阐述FM用于召回的原理与作法
- 线下如何训练
- 线上如何预测
- 如何做到对新用户更友好
---
- 召回随机负采样在实践中到底是怎么做的?提示:
- 你可以离线采样,借助Spark在更大范围内采样,怎么实现?
- 你可以Batch内负采样,怎么实现?
- 你可以混合负采样,怎么实现?
- 阐述以上几种方法的优劣
---
- GCN与DNN在迭代公式上的区别在哪里?(提示:GCN没那么玄,真的只是一个小差别)
- 如何在一个超大规模图上,训练GCN召回模型?希望听到:
- Mini-Batch的训练细节
- 邻居采样,挑出重要邻居
- 邻居采样时有小Trick,否则会造成数据泄漏
- 如何在一个超大规模图上,进行GCN推理,得到各节点的Embedding?
- 希望候选人意识到推理与训练的不同
- 要避免重复计算节点的Embedding
- 要避免"邻居采样"那样的随机性
# 粗排
- 你对改进粗排有什么思路?或者说,你觉得制约粗排模型性能的有哪些因素?
- 粗排双塔与召回双塔的异同?提示有以下4方面的不同
- 物料向量的存储方式
- 样本,特别是负样本的选择
- 损失函数的设计
- 最终用户向量与物料向量的交互方式
- 你知道双塔模型有哪些改进变形?
- 用精排蒸馏粗排应该怎么做?
- 提示:共同训练?两阶段?用什么Loss?各有什么优缺点?
- 思考:蒸馏的假设有问题吗?
- 粗排环节存在哪些"样本选择偏差"?如何纠偏?
# 重排
- 常用的打散方式有哪些?
- MMR的核心思路是什么?
---
- 基于DPP的重排的核心思想是什么?
- 如何构建DPP中的核矩阵L?基于怎样的先验假设?
- 怎么证明如此构建的L是符合我们的先验假设的?
---
- 基于上下文感知的重排模型的原理和流程
- 如何构建样本?
- 如何构建Loss?
- 都应该包含哪些特征?
- 模型训练完毕后,如何排序?(提示:顺序在训练时是已知的,但是预测时是未知的)
# 多任务 & 多场景
- 为什么不为每个目标单独建模?
- 为什么不直接针对最终目标建模?比如直接建模购买率,没必要建模点击率?
---
- 你在工作场景中遇到的多目标推荐的问题?
- 有哪些目标?
- 使用了怎样的模型结构?
- 排序时,我们既希望用户点击,又希望用户点开后观看尽可能长,如何建模?
- 提示:时长目标的单位问题,如果用均方误差,其量纲要远远大于CTR的BCE loss
- 你在训练模型时,是怎么将多个损失融合成一个损失的?
- 你在排序时,是怎么将多个目标的打分融合成一个打分的?
- 提示:要考虑到不同目标的打分存在天然的分布差异
---
- 你遇到过多场景推荐的问题吗?你觉得难点在哪里?
- 你要为一个服务全球的APP设计推荐模型,用户的国籍、语言这些特征要怎么使用?
# 冷启动
- 新用户冷启,如何建模成一个多臂老虎机问题?
- 新物料冷启,如何建模成一个多臂老虎机问题?
---
- 怎么用Epsilon Greedy进行新用户冷启?
- 怎么用UCB进行新用户冷启?
- Bayesian Bandit的基本原理
- Thompson Sampling用于新用户冷启的基本原理与流程
---
- LinUCB用于新闻冷启动的基本原理与流程?
- 这里的谁是老虎机?谁是手柄?
- 如何建模手柄的收益?和哪些因素有关?
- 如何求出每根手柄的参数?
- 候选新闻集合是动态变化的,如何处理?
- 观察到用户反馈后,如何更新每根手柄的收益分布?时间复杂度是什么?
---
- 预测时遇到训练时未见过的新特征,是怎么处理的?
- 训练时遇到训练时未见过的新特征,是怎么处理的?
---
- 简述Meta-Learning的基本原理与流程
- MAML作为一种特殊的meta-learning,特殊在哪里?
- 简述MAML的训练流程
- MAML应用于推荐系统的冷启动
- 每个Task的粒度是什么?
- 哪些参数需要从最优初值初始化?
---
- 简述对比学习的训练流程和应用场景
- 你将对比学习应用于推荐系统的什么场景?
- 对比学习与向量化召回有什么异同?
- 你是怎么做对比学习的?
- 对比学习的样本从哪里来?
- 数据增强是怎么做的?
- 与主任务是怎么协同训练的?
---
- 让你建立一个模型,预测新入库物料的后验CTR,以找到那些潜在爆款?
- 样本怎么选?
- 怎么设计特征?
- 标签怎么收集?(提示:注意一下时间范围)
- 怎么设计Loss?
- 怎么用这个模型?
- 设计对新用户友好的特征?你打算在模型中怎么用这些特征?
# 评估与调试
- AUC的物理含义
- AUC用在评价推荐性能时的缺陷
- GAUC的计算方法
- GAUC的缺点(提示:权重、位置)
- NDCG的思路与计算方法
---
- AUC能不能用于评价召回模型?
- 你在评估召回模型时,主要使用哪些指标?
- MAP的思路与计算方法
---
- AB Test中应该如何划分流量?
- 你在做AB Test时,一般会有哪些注意事项?
- 用通俗语言解释一下什么是p-value?
- 解释一下什么是Type I Error, Type II Error, Power?
---
- 如何知道某个特征在你的模型中的特征重要性?
- 一个多层的DNN,你想压缩一下,如何找到"滥竽充数"那一层?
---
- 你碰到过"线下AUC涨了,线上AB指标没提升"的情况吗?怎么处理解决的?
- 解释一下"特征穿越"现象,及如何解决?
- 你碰到过"老汤模型"带来的麻烦吗?如何解决?
- 新模型小流量上线后,我收集了一批线上数据`D`做测试样本,让新老模型都在`D`上预测并计算GAUC,我的作法有什么问题?正确方式应该怎么做?
- 解释一下"链路一致性"问题。你有没有遇到过"链路一致性"问题?如何解决的?
# 其他
- 以下你两个问题,只要你简历中出现GBDT相关项目,我一般都会问一下,能够答对的人不多
- GBDT中的G代表梯度,那它是谁对谁的梯度?
- 给你一个`mn`的数据集,`m`是样本数,`n`是特征数,问这个梯度向量G有多长?
- 这两个问题实际上是一体的,你只要搞清楚G的含义,自然知道它有多长
- 这两个问题答对了,不代表你懂GBDT,但是答不上来,你肯定不懂GBDT。连G是谁对谁的梯度都搞不清楚,就好比你对外宣称自己是德华的忠实粉丝,但是人家问德华姓什么,你却回答不上来一样尴尬。
这是一个很好的想法!利用推荐系统来优化 Anki 卡片的出现顺序确实可以提高学习效率。结合 Hugging Face 的工具和模型,我们可以实现这个目标。以下是一些相关的想法和知识:
1. 句子相似度计算:
- 使用 Hugging Face 的预训练语言模型(如 BERT、RoBERTa 或 DistilBERT)来获取句子的嵌入向量。
- 计算句子之间的余弦相似度来判断句子的相似程度。
2. 难度评估:
- 使用语言模型评估句子的复杂度(如词汇难度、语法结构)。
- 结合用户的历史表现(如回答正确率、反应时间)来动态调整难度评估。
3. 主题聚类:
- 使用主题建模技术(如 LDA)或基于 transformer 的聚类方法对句子进行分组。
- 这可以帮助将相关主题的句子组织在一起。
4. 间隔重复算法优化:
- 结合传统的间隔重复算法(如 SM-2)和机器学习模型来预测最佳复习时间。
5. 个性化推荐:
- 使用协同过滤或基于内容的推荐方法,考虑用户的学习历史和偏好。
6. 序列推荐:
- 使用序列模型(如 LSTM 或 Transformer)来预测下一个最适合学习的句子。
7. 多模态学习:
- 如果卡片包含音频,可以使用 Hugging Face 的语音识别模型来分析音频特征。
8. 动态难度调整:
- 实时调整推荐策略,根据用户的即时表现调整下一个推荐的难度。
9. 词汇关联:
- 使用 word2vec 或 GloVe 等词嵌入技术,找出句子中关键词的关联性。
10. 错误模式分析:
- 使用自然语言处理技术分析用户的错误模式,推荐能够针对性改善这些错误的句子。
11. 迁移学习:
- 利用在大规模英语语料上预训练的模型,微调到您的具体应用场景。
12. 进度跟踪和适应性学习路径:
- 使用强化学习技术动态调整学习路径,最大化长期学习效果。
实现步骤:
1. 数据准备:将 Anki 卡片内容导出并预处理。
2. 特征提取:使用 Hugging Face 的 Transformers 库提取句子特征。
3. 相似度计算:实现相似度计算函数。
4. 推荐系统设计:结合上述想法,设计适合您需求的推荐算法。
5. 集成到 Anki:开发插件或脚本,将推荐系统集成到 Anki 中。
6. 评估和优化:持续监控系统性能,根据学习效果进行调整。
您对这些想法中的哪一个特别感兴趣?我们可以进一步讨论如何使用 Hugging Face 的工具来实现这些功能。
非常好,让我们深入探讨句子相似度计算和序列推荐这两个方面,并考虑如何使用 Hugging Face 的工具来实现它们。
1. 句子相似度计算:
使用 Hugging Face 的预训练模型来计算句子相似度是一个很好的方法。这里是一个实现思路:
a) 选择模型:
- 可以使用 BERT、RoBERTa 或 DistilBERT 等模型。对于英语句子,"sentence-transformers/all-MiniLM-L6-v2" 是一个不错的选择,它在计算句子相似度方面表现良好。
b) 获取句子嵌入:
- 使用选定的模型将每个句子转换为一个固定长度的向量。
c) 计算相似度:
- 使用余弦相似度来计算句子向量之间的相似程度。
实现概述:
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
# 加载模型和分词器
model_name = "sentence-transformers/all-MiniLM-L6-v2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
def get_sentence_embedding(sentence):
inputs = tokenizer(sentence, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = model(inputs)
return F.normalize(outputs.last_hidden_state.mean(dim=1), p=2, dim=1)
def compute_similarity(sentence1, sentence2):
emb1 = get_sentence_embedding(sentence1)
emb2 = get_sentence_embedding(sentence2)
return torch.nn.functional.cosine_similarity(emb1, emb2).item()
# 使用示例
similarity = compute_similarity("The cat is on the mat", "A feline is resting on a rug")
print(f"Similarity: {similarity}")
```
1. 序列推荐:
对于序列推荐,我们可以使用 Transformer 模型来预测下一个最适合学习的句子。这里是一个实现思路:
a) 数据准备:
- 将用户的学习历史转换为序列数据。
- 每个序列包含用户学习的最后 N 个句子的 ID。
b) 模型选择:
- 可以使用 GPT-2 或 BERT 等模型,根据需要进行微调。
c) 训练过程:
- 使用历史序列预测下一个句子。
- 可以加入额外特征,如难度级别、上次回答的正确性等。
d) 推荐过程:
- 根据用户最近学习的句子序列,预测下一个最适合学习的句子。
实现概述:
```python
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch
# 加载模型和分词器
model_name = "gpt2"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
def prepare_sequence(sentence_ids):
# 将句子ID转换为模型可以理解的格式
return tokenizer.encode(" ".join(map(str, sentence_ids)), return_tensors="pt")
def predict_next_sentence(sequence):
inputs = prepare_sequence(sequence)
with torch.no_grad():
outputs = model(inputs)
predictions = outputs.logits[0, -1, :]
return torch.argmax(predictions).item()
# 使用示例
user_history = [101, 102, 103, 104, 105] # 假设这些是句子ID
next_sentence_id = predict_next_sentence(user_history)
print(f"推荐的下一个句子ID: {next_sentence_id}")
```
将这两种方法结合起来:
1. 使用句子相似度计算来组织和聚类你的 Anki 卡片。
2. 使用序列推荐来决定下一个应该学习的卡片或句子。
实际应用中,你可能需要:
- 对模型进行微调,使其更适合你的具体英语学习场景。
- 考虑句子难度、用户表现等额外因素。
- 实现一个评分系统来持续评估和改进推荐质量。
你对这个方案有什么想法吗?或者你想更深入地了解其中的某个部分?