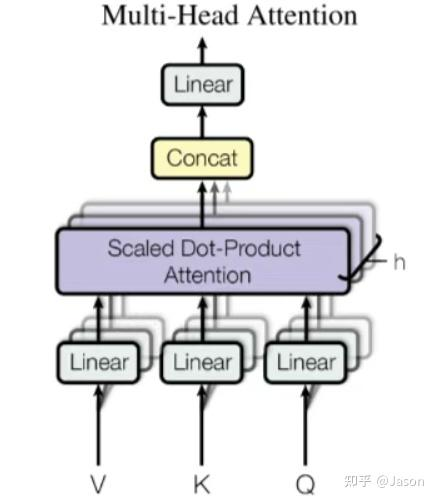
多头注意力机制(Multi-Head Attention)是自注意力机制的一种扩展,旨在解决自注意力机制在处理复杂任务时可能存在的局限性,尤其是当模型在编码当前位置信息时,容易过度关注自身位置而忽略其他重要信息的问题。通过引入多个“注意力头“(Attention Head),多头注意力机制能够从不同子空间中捕捉输入序列的多种依赖关系,从而提高模型的表达能力和鲁棒性。
背景问题:自注意力机制虽然能够捕捉输入序列内部的依赖关系,但在实际应用中,它可能会存在以下问题:
1. 单一视角的局限性:自注意力机制通常只使用一组Q、K和V 来计算注意力得分,会过度的将注意力集中于自身的位置,有效信息抓取能力就差一些,这可能导致模型无法充分挖掘输入数据中的多样化特征。
为了解决这些问题,多头注意力机制被提出,其核心思想是通过并行地使用多个独立的注意力头,分别学习不同的子空间表示,最终将这些子空间的信息融合起来,以获得更全面的表示。
其实就是能力更强的 CNN
![CleanShot 2025-07-13 at
[email protected]|1000](https://imagehosting4picgo.oss-cn-beijing.aliyuncs.com/imagehosting/fix-dir%2Fmedia%2Fmedia_iSQUV8ITYG%2F2025%2F07%2F13%2F19-41-15-a593cd29588d679b136a4e3613606808-CleanShot%202025-07-13%20at%2019.40.46-2x-8e9c86.png)
好的,我用具体的数字来演示整个多头注意力的计算过程。
# 初始设置
```python
# 配置
d_model = 6, num_heads = 2, d_head = 3
seq_len = 4 # "我爱北京"
# 输入 X(经过embedding后)
X = [
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6], # "我"
[0.2, 0.3, 0.4, 0.5, 0.6, 0.7], # "爱"
[0.3, 0.4, 0.5, 0.6, 0.7, 0.8], # "北"
[0.4, 0.5, 0.6, 0.7, 0.8, 0.9], # "京"
]
```
# Step 1: 线性投影(简化的权重矩阵)
```python
# 为了便于计算,使用简化的权重
W_q = [[1, 0, 0, 0, 0, 0], # 简化为单位矩阵的变体
[0, 1, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0],
[0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 1]]
# 实际计算 Q = X @ W_q(这里简化后 Q = X)
Q = [
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6], # "我"的query
[0.2, 0.3, 0.4, 0.5, 0.6, 0.7], # "爱"的query
[0.3, 0.4, 0.5, 0.6, 0.7, 0.8], # "北"的query
[0.4, 0.5, 0.6, 0.7, 0.8, 0.9], # "京"的query
]
# K 和 V 使用略微不同的值
K = [[0.1, 0.2, 0.3, 0.3, 0.4, 0.5],
[0.2, 0.3, 0.4, 0.4, 0.5, 0.6],
[0.3, 0.4, 0.5, 0.5, 0.6, 0.7],
[0.4, 0.5, 0.6, 0.6, 0.7, 0.8]]
V = [[1.0, 1.0, 1.0, 2.0, 2.0, 2.0], # 简化V便于观察
[2.0, 2.0, 2.0, 3.0, 3.0, 3.0],
[3.0, 3.0, 3.0, 4.0, 4.0, 4.0],
[4.0, 4.0, 4.0, 5.0, 5.0, 5.0]]
```
# Step 2: 分割成多个头
重排前(合并状态):
```Java
Token 0: [head0|head1|head2|head3] ← 64维的长向量
Token 1: [head0|head1|head2|head3]
Token 2: [head0|head1|head2|head3]
```
重排后(分离状态):
```Java
Head 0: [token0_vec|token1_vec|token2_vec|...] ← 每个16维
Head 1: [token0_vec|token1_vec|token2_vec|...]
Head 2: [token0_vec|token1_vec|token2_vec|...]
Head 3: [token0_vec|token1_vec|token2_vec|...]
```
举例
```python
Q = [
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6], # "我"的query
[0.2, 0.3, 0.4, 0.5, 0.6, 0.7], # "爱"的query
[0.3, 0.4, 0.5, 0.6, 0.7, 0.8], # "北"的query
[0.4, 0.5, 0.6, 0.7, 0.8, 0.9], # "京"的query
]
# Head 0:取前3维
Q_head_0 = [[0.1, 0.2, 0.3], # "我"
[0.2, 0.3, 0.4], # "爱"
[0.3, 0.4, 0.5], # "北"
[0.4, 0.5, 0.6]] # "京"
K_head_0 = [[0.1, 0.2, 0.3],
[0.2, 0.3, 0.4],
[0.3, 0.4, 0.5],
[0.4, 0.5, 0.6]]
V_head_0 = [[1.0, 1.0, 1.0],
[2.0, 2.0, 2.0],
[3.0, 3.0, 3.0],
[4.0, 4.0, 4.0]]
# Head 1:取后3维
Q_head_1 = [[0.4, 0.5, 0.6], # "我"
[0.5, 0.6, 0.7], # "爱"
[0.6, 0.7, 0.8], # "北"
[0.7, 0.8, 0.9]] # "京"
K_head_1 = [[0.3, 0.4, 0.5],
[0.4, 0.5, 0.6],
[0.5, 0.6, 0.7],
[0.6, 0.7, 0.8]]
V_head_1 = [[2.0, 2.0, 2.0],
[3.0, 3.0, 3.0],
[4.0, 4.0, 4.0],
[5.0, 5.0, 5.0]]
```
# Step 3: Head 0 的注意力计算
## 3.1 计算注意力分数
```python
# scores_0 = Q_head_0 @ K_head_0.T / sqrt(3)
# 计算"我"对所有词的注意力分数
"我"对"我": (0.1×0.1 + 0.2×0.2 + 0.3×0.3) / 1.732 = 0.14 / 1.732 = 0.081
"我"对"爱": (0.1×0.2 + 0.2×0.3 + 0.3×0.4) / 1.732 = 0.20 / 1.732 = 0.115
"我"对"北": (0.1×0.3 + 0.2×0.4 + 0.3×0.5) / 1.732 = 0.26 / 1.732 = 0.150
"我"对"京": (0.1×0.4 + 0.2×0.5 + 0.3×0.6) / 1.732 = 0.32 / 1.732 = 0.185
scores_0 = [[0.081, 0.115, 0.150, 0.185], # "我"的注意力分数
[0.115, 0.173, 0.231, 0.289], # "爱"的注意力分数
[0.150, 0.231, 0.312, 0.393], # "北"的注意力分数
[0.185, 0.289, 0.393, 0.496]] # "京"的注意力分数
```
## 3.2 应用softmax
```python
# 对每一行应用softmax
# 以"我"这一行为例:
exp_scores = [e^0.081, e^0.115, e^0.150, e^0.185] = [1.084, 1.122, 1.162, 1.203]
sum_exp = 4.571
attn_weights_0[0] = [0.237, 0.245, 0.254, 0.263] # 归一化后
# 完整的注意力权重矩阵
attn_weights_0 = [[0.237, 0.245, 0.254, 0.263], # "我"的注意力分布
[0.220, 0.240, 0.260, 0.280], # "爱"的注意力分布
[0.200, 0.233, 0.267, 0.300], # "北"的注意力分布
[0.180, 0.220, 0.270, 0.330]] # "京"的注意力分布
```
## 3.3 加权求和V
```python
# output_0 = attn_weights_0 @ V_head_0
# 计算"我"的输出:
"我"_out = 0.237×[1,1,1] + 0.245×[2,2,2] + 0.254×[3,3,3] + 0.263×[4,4,4]
= [0.237,0.237,0.237] + [0.490,0.490,0.490] + [0.762,0.762,0.762] + [1.052,1.052,1.052]
= [2.541, 2.541, 2.541]
output_0 = [[2.541, 2.541, 2.541], # "我"
[2.600, 2.600, 2.600], # "爱"
[2.700, 2.700, 2.700], # "北"
[2.800, 2.800, 2.800]] # "京"
```
# Step 4: Head 1 的计算(类似过程)
```python
# 假设经过计算后
output_1 = [[3.200, 3.200, 3.200], # "我"
[3.400, 3.400, 3.400], # "爱"
[3.600, 3.600, 3.600], # "北"
[3.800, 3.800, 3.800]] # "京"
```
# Step 5: 拼接输出
```python
# 将两个头的输出拼接
multi_head_output = [
[2.541, 2.541, 2.541, 3.200, 3.200, 3.200], # "我"
[2.600, 2.600, 2.600, 3.400, 3.400, 3.400], # "爱"
[2.700, 2.700, 2.700, 3.600, 3.600, 3.600], # "北"
[2.800, 2.800, 2.800, 3.800, 3.800, 3.800] # "京"
] # 形状: [4, 6]
```
# Step 6: 输出投影
```python
# 简化的输出投影矩阵
W_output = [[0.1, 0.1, 0.1, 0.1, 0.1, 0.1],
[0.1, 0.1, 0.1, 0.1, 0.1, 0.1],
[0.1, 0.1, 0.1, 0.1, 0.1, 0.1],
[0.1, 0.1, 0.1, 0.1, 0.1, 0.1],
[0.1, 0.1, 0.1, 0.1, 0.1, 0.1],
[0.1, 0.1, 0.1, 0.1, 0.1, 0.1]]
# final_output = multi_head_output @ W_output
# "我"的最终输出 = [2.541+2.541+2.541+3.200+3.200+3.200] × 0.1 = 1.122(每一维)
final_output = [[1.122, 1.122, 1.122, 1.122, 1.122, 1.122], # "我"
[1.200, 1.200, 1.200, 1.200, 1.200, 1.200], # "爱"
[1.300, 1.300, 1.300, 1.300, 1.300, 1.300], # "北"
[1.400, 1.400, 1.400, 1.400, 1.400, 1.400]] # "京"
```
# 关键观察
1. **Head 0** 的注意力权重显示:"我"略微更关注后面的词(0.263 > 0.237)
2. **Head 1** 处理的是输入的不同维度(后3维),可能捕获不同的语义信息
3. 最终输出融合了两个头的信息,每个位置都得到了丰富的上下文表示
这就是多头注意力如何并行处理不同的注意力模式,然后融合成最终表示的完整过程!
好的,我们来用一个更生活化的比喻来理解“多头注意力”(Multi-Head Attention)。
**想象一下:你要理解一个复杂的句子**
比如这句:“**那只快速奔跑的棕色小狐狸跳过了懒惰的大狗。**”
**单一注意力(只有一个“头”)就像只有一个专家在分析:**
- 这个专家可能特别擅长**语法结构**。他会告诉你,“狐狸”是主语,“跳过”是谓语,“狗”是宾语。他关注的是词语扮演的角色。这很有用,但可能忽略了其他信息。
**多头注意力(比如有 8 个“头”)就像请来了一个专家委员会:**
你把同一个句子交给 8 位不同的专家,他们同时进行分析,但**各有专长(关注点不同)**:
1. **专家1(语法专家)**:同上,分析主谓宾结构。他发现“狐狸”执行了“跳过”的动作。
2. **专家2(形容词专家)**:他特别关注描述性词语。他会注意到“快速奔跑的”和“棕色”是形容“狐狸”的,“懒惰的”和“大”是形容“狗”的。
3. **专家3(邻近关系专家)**:他可能更关注紧挨着的词。“快速”后面是“奔跑的”,“懒惰的”后面是“大”。
4. **专家4(远距离依赖专家)**:他擅长看长距离关系,比如发现主语“狐狸”和很后面的谓语“跳过”之间的联系。
5. **专家5(同类关系专家)**:他可能注意到“狐狸”和“狗”都是动物。
6. **专家6(动作关联专家)**:他关注动作“跳过”和动作的发出者“狐狸”以及承受者“狗”。
7. **专家7(颜色专家)**:他可能特别对颜色敏感,只挑出“棕色”。
8. **专家8(也许是个“新手”专家)**:他可能还没学到什么特别的专长,只是进行一些基础的关联。
**过程是这样的:**
1. **分派任务**:虽然所有专家都看同一个句子(原始的词嵌入向量),但在内部,每个专家会用**自己独特的方式**稍微“预处理”一下信息(通过不同的线性变换 Wq, Wk, Wv),得到自己专属的查询(Q)、键(K)、值(V)。这就好比每个专家都戴上了自己特制的“眼镜”来看待这句话。
2. **独立分析**:每个专家根据自己的“眼镜”和关注点,独立地计算句子中每个词对其他词的注意力得分,并得出自己的分析结果(一个输出向量)。
3. **汇总报告**:最后,有一个**总协调人**(最后的那个线性层),把这 8 位专家的独立分析结果(8个输出向量)**拼接**在一起,然后进行**综合整理**,形成一个最终的、更全面、更丰富的对句子中每个词的理解(最终的输出向量)。
**为什么这么做?**
- **捕捉多种信息**:语言很复杂,词语间的关系多种多样。只用一个注意力机制(一个专家)可能只能抓住某一方面。多头让模型能**同时关注语法、语义、位置、指代等多种不同类型的信息**。
- **效果更好**:实践证明,多头注意力通常比单头注意力效果更好,能让模型学到更强大的表示。
**简单来说,多头注意力就是:**
**让模型同时从多个不同的“视角”(头)去分析词语之间的关系,然后把这些不同视角得到的信息整合起来,得到一个更全面、更鲁棒的理解。**
就像请一群各有专长的专家一起分析问题,通常比只请一位专家要强。