[[中文概念词典(CCD)]]
以单词 **"learn"** 为例,WordNet的数据结构通常如下:
下面是添加了**中文字段名称**的 WordNet 数据格式示例(以单词 **bad** 为例):
|字段名称(英文)|字段名称(中文)|示例内容|
|---|---|---|
|Synset Name|同义词集名称|bad.a.01|
|Part of Speech|词性|a(形容词)|
|Definition|定义|having undesirable or negative qualities|
|Examples|示例|["a bad report card", "bad habits", "a bad impression"]|
|Lemmas|词条|["bad"]|
|Hypernyms|上位词|["evil.a.01"](更广义的词义,泛指负面特质)|
|Hyponyms|下位词|["atrocious.a.01", "abominable.a.01", "terrible.a.01"](更具体或更强烈的负面含义)|
这样清晰地标明中英文对照,便于理解各字段含义和使用 WordNet 数据进行分析。
|字段名称|示例内容|
|---|---|
|Synset Name|learn.v.01|
|Part of Speech|v (动词)|
|Definition|gain knowledge or skills|
|Examples|["She learned dancing from her sister."]|
|Lemmas|["learn", "larn", "acquire"]|
|Hypernyms|["study.v.01"](更广义词)|
|Hyponyms|["catch_up.v.02", "memorize.v.01", "study.v.04"](更具体词)|
WordNet的数据以这样结构化的方式呈现,有助于深入理解词义之间的关系。
# Human language and word meaning
人类之所以比类人猿更"聪明",是因为我们有语言,因此是一个人机网络,其中人类语言作为网络语言。人类语言具有 **信息功能** 和 **社会功能**。
据估计,人类语言只有大约5000年的短暂历。语言是人类变得强大的主要原因。写作是另一件让人类变得强大的事情。它是使知识能够在空间上传送到世界各地,并在时间上传送的一种工具。
但是,相较于如今的互联网的传播速度而言,人类语言是一种缓慢的语言。然而,只需人类语言形式的几百位信息,就可以构建整个视觉场景。这就是自然语言如此迷人的原因。
**How do we represent the meaning of a word?**
***meaning***
- 用一个词、词组等表示的概念。
- 一个人想用语言、符号等来表达的想法。
- 表达在作品、艺术等方面的思想
理解意义的最普遍的语言方式(**linguistic way**): 语言符号与语言符号的意义的转化
$
\boxed{\text{signifier(symbol)}\Leftrightarrow \text{signified(idea or thing)}} \\
= \textbf{denotational semantics}
$
> denotational semantics 指称语义
**How do we have usable meaning in a computer?**
***WordNet***, 一个包含同义词集和上位词("is a"关系) ***synonym sets and hypernyms*** 的列表的辞典

**Problems with resources like WordNet**
- 作为一个资源很好,但忽略了细微差别
- 例如"proficient"被列为"good"的同义词。这只在某些上下文中是正确的。
- 缺少单词的新含义
- 难以持续更新
- 例如 wicked, badass, nifty, wizard, genius, ninja, bombest
- 主观的
- 需要人类劳动来创造和调整
- 无法计算单词相似度
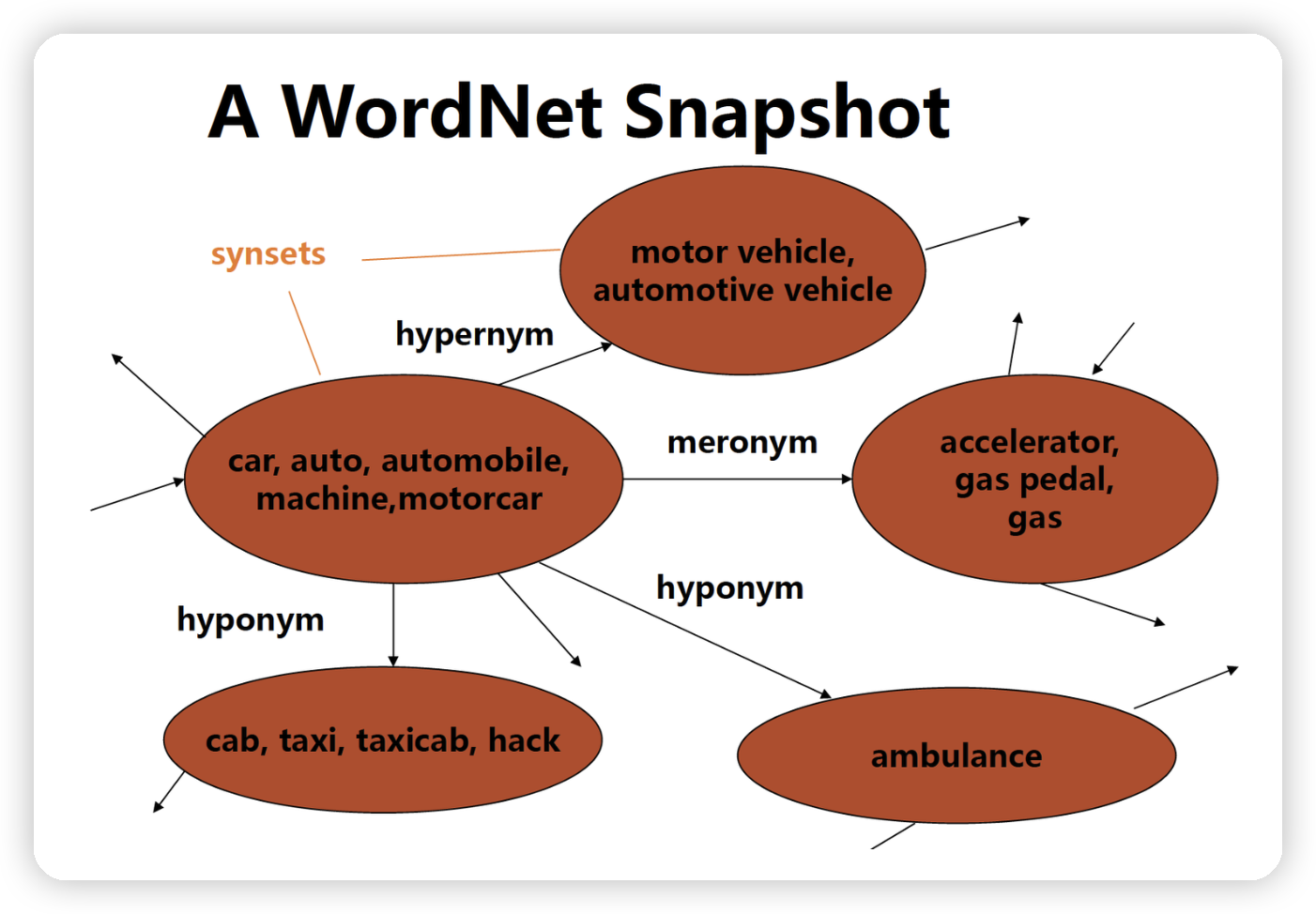
知道这个概念是看一篇介绍 [李飞飞](李飞飞.md) 的文章。语言的世界 WordNet,视觉的世界 [ImageNet](ImageNet.md)。将物理世界建模于二进制世界,是后来 [人工智能@](人工智能@.md) 能够爆发威力的基础。
看了一下 WordNet 查询接口返回的 JSON 结构。同义词 set 是一个比较高的层级,很符合自己以前写的那个 telegrambot 时候的思路,对于词汇的掌握来说,确实词以群分是第一步,而后才是作为一个整体去寻找他们的父子节点。
另外,可以在实际使用中逐渐积累英文世界和中文世界的 gap,就是有些单词,在纯英文世界观的 WordNet 中并不会归为一类,但是由于英译中的原因,导致我们被译文误导,基于中文世界观会在脑海中将他们分到一起。
---
http://wordnetweb.princeton.edu/perl/webwn
WordNet 是一个在 20 世纪 80 年代由 Princeton 大学的著名认知心理学家 George Miller 团队构建的一个大型的英文词汇数据库。**名词、动词、形容词和副词以同义词集合(synsets)的形式存储在这个数据库中。每一个 synset 代表了一个同义词集合。各个 synsets 之间通过语义关系和词性关系等边连接。
| | s | | |
| ------------- | -------- | ----------------------- | ------- |
| 节点 | SYNSET | 图节点,同义词集合 | |
| | SYNONYMS | | |
| 边 / RELATIONS | 垂直边 | HYPERNYMS | 上位词,更泛化 |
| | | HYPONYMS | 下位词,更具体 |
| | | ENTAILMENTS: | 蕴含 |
| | | DERIVATIONALLY_RELATED: | 变形、派生 |
| | 水平边 | ANTONYMS: | 反义词 |
- **同义关系** (Synonymy)
- 描述相同或相似含义的词
- 例如:'car' 和 'automobile'
- **反义关系** (Antonymy)
- 描述相反含义的词
- 例如:'hot' 和 'cold'
- **上/下位关系** (Hypernymy/Hyponymy)
- 描述概念的层次结构
- 上位词:"is-a" 关系
- 下位词:"type-of" 关系
- 例如:'animal' -> 'dog' -> 'poodle'
- **整体/部分关系** (Holonymy/Meronymy) 分为三种子类型:
- **部件关系** (Part)
- 描述物体的组成部分
- 例如:'car' 有 'wheel'
- **成员关系** (Member)
- 描述群体与个体的关系
- 例如:'forest' 有 'tree'
- **物质关系** (Substance)
- 描述材料构成关系
- 例如:'water' 构成 'lake'
- **派生关系** (Derivation)
- 描述词形变化关系
- 例如:'teach' 和 'teacher'
- **主题域关系** (Domain)
- 描述词属于的知识领域
- 例如:'biology'、'sports'
- **蕴含关系** (Entailment) - 主要用于动词
- 描述动作的必然关系
- 例如:'snore' 蕴含 'sleep'
- **原因关系** (Cause) - 主要用于动词
- 描述动作的因果关系
- 例如:'kill' 导致 'die'
# 使用思路
1. 可忽视的差异:利用 wordnet 拿到 SYNONYMS,增大对用户的容错
2. 需要重视的差异:拿到上下位词,进一步去查历史使用记录
NLPer 都说好的英文词库——WordNet!- hemingkx 的文章 - 知乎
https://zhuanlan.zhihu.com/p/366370332
http://wordnetweb.princeton.edu/perl/webwn
可能要把里面的这种词与词的关系,结合上 COCA 的词频一起使用。
1. 比如下面这份 wordnet 接口数据,可以让 AI 选择按照哪个 set 群走,然后给出这个 set 群里的上下位、以及派生词
2. 把 1 中挑出的这些词用 coca 高频过滤,比如定义为只需要关注前 20000
3. 把 2 中过滤后的词,去用户的使用历史中搜出对应的语境和对错
4. 使用中逐渐积累英文世界和中文世界的 gap,就是纯英文的 wordnet 中并不会归为一类,但是由于英译中的原因,导致我们被译文误导,而会在脑海中将他们分到一起。
让我使用 Python 代码来展示 NLTK 接口原生返回的数据结构:
对不起,让我重新试一下:
执行这段代码,你会得到类似这样的 JSON 结构:
```json
{
"influence.v.01": {
"name": "influence.v.01",
"lemmas": ["influence", "act_upon", "work"],
"definition": "have and exert influence or effect",
"examples": ["The artist's work influenced the young painter",
"She worked on her friends to support the political candidate"],
"pos": "v",
"offset": 2153218,
"lexname": "verb.perception",
"lemma_infos": [
{
"name": "influence",
"syntactic_marker": "",
"count": 40,
"derivationally_related_forms": [
["influence", "influence.n.01"]
],
"antonyms": []
},
{
"name": "act_upon",
"syntactic_marker": "",
"count": 2,
"derivationally_related_forms": [],
"antonyms": []
},
{
"name": "work",
"syntactic_marker": "",
"count": 1,
"derivationally_related_forms": [
["work", "work.n.01"]
],
"antonyms": []
}
],
"relations": {
"hypernyms": [
{
"name": "affect.v.01",
"definition": "have an effect upon"
}
],
"hyponyms": [
{
"name": "manipulate.v.01",
"definition": "influence or control shrewdly or deviously"
},
{
"name": "prejudice.v.02",
"definition": "influence (somebody's) opinion in advance"
}
// ... 更多下位词
],
"part_meronyms": [],
"part_holonyms": [],
"substance_meronyms": [],
"substance_holonyms": [],
"member_meronyms": [],
"member_holonyms": [],
"entailments": [],
"causes": []
}
},
"determine.v.02": {
// 第二个同义词集的类似结构
},
"charm.v.04": {
// 第三个同义词集的类似结构
}
}
```
关键数据结构解释:
1. **顶层结构**:
- 以同义词集名称为键
- 每个同义词集包含完整的信息
2. **同义词集基本信息**:
```json
{
"name": "同义词集标识符",
"lemmas": ["词条列表"],
"definition": "定义",
"examples": ["例句"],
"pos": "词性",
"offset": "数据库偏移量",
"lexname": "词典文件名"
}
```
3. **词条级信息**:
```json
"lemma_infos": [
{
"name": "词条名称",
"count": "使用频率",
"derivationally_related_forms": ["派生关系"],
"antonyms": ["反义词"]
}
]
```
4. **关系信息**:
```json
"relations": {
"hypernyms": ["上位词"],
"hyponyms": ["下位词"],
"part_meronyms": ["部分关系词"],
// ... 其他关系
}
```
这种数据结构的特点:
1. **层次性**:
- 清晰的词义层次
- 完整的关系网络
2. **完整性**:
- 包含所有核心信息
- 保留原始数据结构
3. **可用性**:
- 便于程序处理
- 支持复杂查询
4. **扩展性**:
- 可以轻松添加新的关系类型
- 可以根据需要调整数据结构
这个原始数据结构为后续的应用提供了基础:
1. **词义分析**
2. **语义网络构建**
3. **文本相似度计算**
4. **知识图谱构建**
# 本质是四个图
WordNet 的大多数关系都只将来自同一词性(Part Of Speech)的词联系起来。因此,wordnet 实际上由四个子图组成,分别是名词、动词、形容词和副词。
## 3.3 动词图
动词的 synsets 集合也有类似上述的层次结构。
在这种层级结构中,越靠近叶节点的动词表示动作越来越具体,比如 communicate->talk->whisper(音量越来越具体),move->jog->run(速度越来越具体),like->love->idolize(情感越来越具体)。另外,某些动作与完成这些动作时所必经的一些动作之间也有单向边连接。比如 buy->pay,succeed->try,show->see。
## 3.4 形容词图
形容词 synsets 之间的关系是根据反义词关系来组织的。
比如 dry 和 wet,old 和 young。这些反义词关系表示了 synsets 之间的强语义约束性。而每一个反义词关系两边的形容词 synset 又与很多语义相似的形容词相连,比如 dry 和 parched、arid、dessicated 等相连,wet 和 soggy、waterlogged 等相连。
## 3.5 副词图
WordNet 中仅有少量的副词 synsets,比如 hardly、mostly、really 等。也就是朱伟说的副词最不重要了,都是表示程度的,信息熵很低。
## 4、跨词性关系
跨词性的 synsets 关系很少,大部分都是词法关系,比如 observe(动词)、observant(形容词)、observation(名词)。还有一些关系表示名词是动词代表动作的某个语义角色,比如 sleeping car 是 sleep 的 LOCATION,painter 是 paint 的 AGENT 等等。