filesystem
https://mcp.so/server/filesystem/modelcontextprotocol
https://smithery.ai/
| 特性/技术 | MCP SSE | STDIO | WebSocket | HTTP Stream Transport (新版推荐) |
| ----------- | ---------------------------- | ----------------------- | ------------ | ----------------------------- |
| **协议基础** | 基于 HTTP 的 Server-Sent Events | 标准输入输出流 | WebSocket 协议 | 基于 HTTP 的流式传输 |
| **通信方向** | 单向(服务器→客户端)| 双向 | 全双工 | 双向流式通信 |
| **适用场景** | 远程工具调用/数据推送 | 本地进程间通信 | 实时双向交互 | 远程工具调用/流式响应 |
| **实时性** | 高(服务器主动推送)| 高 | 极高 | 高 |
| **复杂度** | 低(自动重连/UTF-8编码)| 极低 | 中(需握手协议)| 中 |
| **多客户端支持** | ✅ 是 | ❌ 单进程 | ✅ 是 | ✅ 是 |
| **跨域支持** | 需 CORS 配置 | 不适用 | 需 CORS 配置 | 需 CORS 配置 |
| **二进制支持** | ❌ 仅文本 | ✅ 是 | ✅ 是 | ✅ 是 |
| **MCP 标准化** | 旧版标准(已弃用)| 现行标准 | 未原生支持 | 现行标准 |
| **典型延迟** | 50-200ms | <1ms | 20-100ms | 50-200ms |
| **适用场景案例** | 天气数据推送/工具状态更新 | 本地 CLI 工具集成 | 实时协作编辑 | 流式 AI 响应/大文件传输 |
| **消息格式** | JSON-RPC 2.0 over SSE | JSON-RPC 2.0 over STDIO | 自定义二进制协议 | JSON-RPC 2.0 over HTTP Stream |
| **TLS 支持** | ✅ (HTTPS) | ❌ | ✅ (WSS) | ✅ (HTTPS) |
| **浏览器兼容性** | 现代浏览器 | 不适用 | 现代浏览器 | 现代浏览器 |
| **心跳机制** | 自动保持连接 | 不需要 | 需手动实现 | 自动保持连接 |
| **推荐指数** | ⚠️ 遗留系统维护 | ★★★★★ 本地开发 | ★★☆☆☆ 非标准场景 | ★★★★★ 新项目 |
| | 本地不需要启进程 | 本地需要启一个进程 | | |
瘦 LLM(精简的大语言模型)通过 **Model Context Protocol(MCP)** 与外部数据源和工具进行交互,以获取所需的信息和功能。那么,瘦 LLM 如何知道调用哪个 MCP 服务器,以及最初的信息从何而来呢?
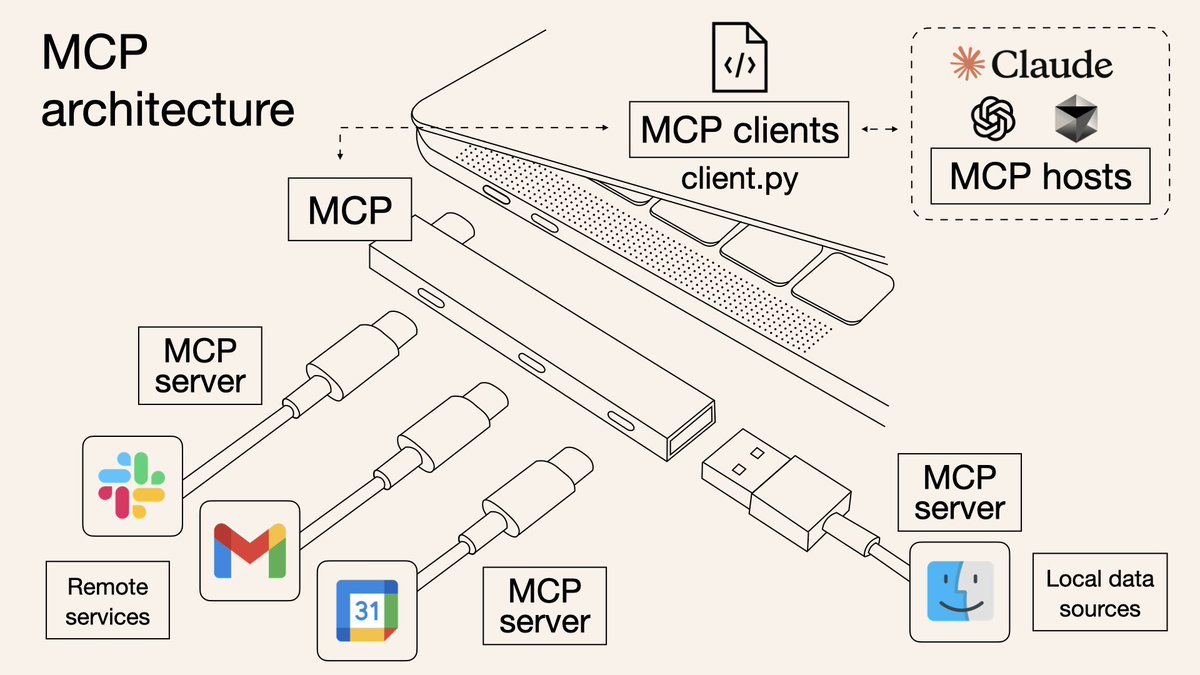
**1. MCP 的架构与组件**
MCP 采用客户端-服务器架构,主要包括以下组件:
- **MCP 主机(Host)**:运行 LLM 的应用程序,如 Claude Desktop 或其他 AI 工具。
- **MCP 客户端(Client)**:内置于主机中的组件,负责与 MCP 服务器建立连接。
- **MCP 服务器(Server)**:提供特定功能或数据的服务端程序,通过标准化的 MCP 协议与客户端通信。
**2. 瘦 LLM 如何确定调用哪个 MCP 服务器?**
当用户提出请求时,瘦 LLM 需要确定调用哪个 MCP 服务器来满足该请求。这一过程通常涉及以下步骤:
- **意图识别**:LLM 解析用户输入,理解其意图和需求。
- **服务发现**:根据识别出的意图,LLM 查找可用的 MCP 服务器列表,确定哪些服务器能够提供所需的功能或数据。
- **服务器选择**:从候选服务器中选择最合适的 MCP 服务器进行调用。
为了实现这一过程,LLM 通常需要预先配置或动态获取 MCP 服务器的相关信息,包括服务器的功能描述、访问方式等。例如,Anthropic 的 Claude Desktop 应用程序内置了 MCP 客户端,可以自动发现和连接到预定义的 MCP 服务器。citeturn0search7
**3. 最初的信息从哪里来?**
最初,瘦 LLM 需要知道有哪些 MCP 服务器可用以及它们提供的功能。这些信息通常通过以下方式获取:
- **预配置**:在 LLM 的配置文件或设置中,预先定义可用的 MCP 服务器及其功能描述。
- **服务注册与发现机制**:MCP 可能提供服务注册和发现机制,允许 MCP 服务器在启动时向中央注册中心注册其功能,LLM 可以从该注册中心获取最新的服务器列表和功能信息。
通过上述方式,瘦 LLM 能够动态地了解和调用适当的 MCP 服务器,以满足用户的请求。
**参考资料:**
- [Model Context Protocol: Introduction](https://modelcontextprotocol.io/introduction)
- [Introducing the Model Context Protocol - Anthropic](https://www.anthropic.com/news/model-context-protocol)
---
将**Model Context Protocol(MCP)**与区块链技术融合具有一定的可行性和潜在优势。MCP旨在为大型语言模型(LLMs)与外部数据源和服务之间的集成提供标准化接口,而区块链技术以其去中心化、透明性和不可篡改性,为数据安全和可信交互提供了坚实基础。
**融合的潜在优势:**
1. **数据安全与隐私保护:**MCP通过标准化的数据访问接口,减少了直接接触敏感数据的环节,降低数据泄露风险。区块链的加密和分布式存储特性可进一步增强数据的安全性和隐私保护。citeturn0search0
2. **可信数据源:**区块链的不可篡改特性确保了数据的真实性和完整性。将MCP与区块链结合,可以为AI模型提供经过验证的、可信的数据源,提升模型输出的准确性和可靠性。
3. **去中心化的AI生态:**通过区块链技术,MCP可以实现去中心化的AI服务网络,避免单一实体的垄断,促进公平竞争和创新。
**挑战与考虑:**
- **性能与扩展性:**区块链的交易处理速度和扩展性可能无法满足高频率、大规模的AI数据交互需求。需要探索高效的共识机制和链下解决方案,以提升性能。
- **技术复杂性:**将MCP与区块链融合涉及多种技术的整合,可能增加系统的复杂性,需谨慎设计和实施。
综上所述,MCP与区块链的融合在理论上具有可行性,但在实际应用中需要克服性能、扩展性和技术复杂性等挑战。随着技术的不断发展和优化,这种融合有望为AI领域带来新的机遇和创新。
---
## 📌 一、MCP 到底是什么?
**MCP (Model Context Protocol)** 是一种开放标准协议和框架,专门用于帮助**大语言模型(LLMs)**与各种外部数据源、工具、知识服务快速高效地进行连接和交互。类比来说:
- **LLM(大语言模型)** = Windows 操作系统
- **Cursor等AI工具** = 鼠标、键盘等外设
- **MCP** = USB 接口(标准化的接口协议)
MCP 的目标是将知识、工具、提示词(Prompt)标准化对外提供,任何人可以开发和托管自己的 MCP 服务,随时上线、下线。
具体地说,MCP 提供三类能力的扩展:
- **Resources**(外部知识和数据源)
- **Tools**(外部功能调用)
- **Prompts**(标准化的提示词模板)
---
## 📌 二、为什么需要 MCP?(当前问题)
目前的 LLM(称为"胖 LLM")面临的问题:
1. **知识过时、训练成本巨大**:
- LLM 知识只能通过庞大的参数和数据预训练,信息常常过时。
2. **难以轻量化部署**:
- 巨大的模型难以本地部署,成本极高。
3. **爬虫和信息质量问题**:
- 依靠网络爬取外部数据质量差,且易受反爬措施影响。
4. **创作者经济生态破坏**:
- LLM 公司免费爬取知识,但创作者未获得收益,导致内容质量下降。
5. **外部功能难以精确实现**:
- 无法准确调用外部系统或 API。
因此需要一种**瘦 LLM + MCP**的新架构。
---
## 📌 三、瘦 LLM + MCP 架构演进
文章提出"瘦 LLM"架构:
- **胖 LLM (当前模型)**:
- 大规模预训练数据 → 模型参数 → 直接回答用户问题。
- **瘦 LLM + MCP**:
- 仅专注于语言理解和信息协调(Perception & Reasoning)。
- 外部知识、功能通过 MCP 动态调用。
- 更轻量,训练更低成本、更灵活部署。
架构演进方向:
- 瘦 LLM 仅处理人类交互信息(语音、文字、图像甚至气温、重力等)。
- 通过 MCP 协议调用外部服务器(MCP Servers)获取知识和执行功能。
- 模型和知识分离,提高实时性、灵活性与效率。
---
## 📌 四、MCP 带来的价值和未来展望
作者兴奋于 MCP 的原因是,它可能解决他多年思考的三个重要问题:
### ① 如何让普通人(非科学家/天才)参与 AI 并获得收入?
- 任何有专业知识的人(如鸟类爱好者)都能托管 MCP Server 并收费。
- 实现了更加精准的**AI创作者经济**:
- 调用次数、token 数量精准统计并获得收入。
- 创作者不再抵制 AI,而是积极参与并获得收益。
### ② AI 与 Ethereum 如何实现双赢结合?
- 基于 Ethereum 构建去中心化的 **OpenMCP.Network**:
- MCP Server 提供者通过智能合约自动获得收入,激励高质量内容。
- 使用以太坊提供透明、公平、抗审查的激励分配机制。
- 开发以太坊链上专门的 MCP 服务,如智能钱包(AA Wallet),实现智能合约开发更便利、更安全、更易用。
### ③ 如何实现 AI 的去中心化(AI d/acc),避免垄断和 AGI 风险?
- MCP Servers 实现知识和功能去中心化,打破垄断:
- 没有公司可掌控所有 MCP Servers。
- 创作者若认为激励不公,可拒绝特定 LLM 提供商的调用。
- MCP Servers 细粒度权限控制,保护隐私和版权。
- AGI 能力分散在各个 MCP Servers 中,避免了中心化 AI 失控毁灭人类的风险:
- 一旦关停 MCP Servers,LLM 仅能提供基础对话,无实质威胁。
---
## 📌 五、MCP 的本质思想(深层次思考)
文章背后的本质思考是:
- **去中心化的 AI 架构(瘦 LLM + MCP)** 将成为未来 AI 的主要发展趋势,打破当前以 OpenAI、Anthropic 等大型公司为主导的中心化模式。
- 这种架构不仅是技术上的创新,更是经济和社会架构上的巨大进步,能有效激励个体创作者参与 AI 产业,共享 AI 带来的经济效益。
- 以太坊(Ethereum)为这种生态提供了天然的经济与治理基础,通过智能合约实现可信激励、抗审查、安全与隐私保护等功能,从而实现 AI 与区块链的双赢。
作者将 MCP 看作是实现 AI 去中心化、推动公平创作者经济的重要基础设施,是继 ChatGPT 之后最重要的创新之一。
---
## 📌 六、作者对未来的预测(剧本演进)
1. MCP 协议将成为行业标准,各大公司争相布局。
2. 专注语言理解的瘦 LLM 出现,自动调用 MCP Servers。
3. 出现专门的 MCP Network 服务提供商。
4. 若 Ethereum 承载 MCP 网络经济系统,Ethereum 网络交易量(Transactions)将大幅提升(预计150倍左右),推动区块链生态进一步发展。
---
## 🚀 文章整体的核心逻辑和本质
**从中心化的胖模型 → 去中心化瘦模型 + MCP 架构 → 创建公平、透明的 AI 创作者经济 → Ethereum+AI 双赢**。
作者认为这套模式:
- 能充分激活个体创作者积极参与 AI 产业。
- 避免中心化巨头公司对 AI 的垄断与风险(如 AGI 威胁)。
- 促进 AI 与区块链(尤其 Ethereum)的深度融合,创造新的生态繁荣。
文章表达了作者对 AI 行业演进、创作者经济、以太坊与 AI 融合、去中心化生态的强烈看好,并认为 MCP 架构将显著改变未来的产业结构和经济模式。
---
1. **访问Anthropic的官方网站**:Anthropic在其网站上提供了关于MCP的介绍和相关资源[1](https://www.anthropic.com/news/model-context-protocol)。
2. **GitHub仓库**:MCP的GitHub仓库包含了详细的文档、规范和SDK[4](https://github.com/modelcontextprotocol)。
3. **MCP社区论坛**:在MCP的社区论坛中,你可以与其他开发者讨论问题并获取帮助[4](https://github.com/modelcontextprotocol)。
让我分析一下 MCP 与普通 RPC 和 HTTP 协议的主要区别:
1. **结构化的上下文传递**
从代码实现来看,MCP 使用了标准的 JSON-RPC 2.0 协议作为底层通信协议,但它的特殊之处在于:
```python
class MCPRequest(BaseModel):
jsonrpc: str = "2.0"
method: str
params: dict
id: int
context: Optional[Dict[str, Any]] = None
model_state: Optional[Dict[str, Any]] = None
conversation_history: Optional[List[Dict]] = None
class MCPResponse(BaseModel):
jsonrpc: str = "2.0"
result: Optional[Dict[str, Any]] = None
error: Optional[Dict[str, Any]] = None
id: int
```
这个结构不仅传递了方法调用信息,还可以包含 AI 模型所需的上下文信息,使得 AI 工具能更好地理解和处理请求。
1. **专注于 AI 工具的交互模式**
与普通 RPC/HTTP 的区别:
- **普通 HTTP 协议**:
- 是一个通用的请求-响应协议
- 主要关注资源的 CRUD 操作(GET/POST/PUT/DELETE)
- 无状态,每个请求都是独立的
- 不直接支持双向通信
- **普通 RPC 协议**:
- 关注远程方法调用
- 通常是同步的请求-响应模式
- 主要用于服务间的函数调用
- **MCP 协议**:
- 专门为 AI 工具设计的通信协议
- 支持上下文感知的操作
- 可以传递更丰富的语义信息
- 设计用于 AI 模型和外部服务的交互
1. **数据源抽象**
从代码实现可以看到,MCP 提供了一个统一的接口来访问不同类型的数据源:
```python
# mcp_service.py 中的方法处理
if rpc_request.method == "read_file":
result = handle_read_file(rpc_request.params)
elif rpc_request.method == "write_file":
result = handle_write_file(rpc_request.params)
elif rpc_request.method == "list_directory":
result = handle_list_directory(rpc_request.params)
```
这种设计允许 AI 模型通过统一的接口访问不同类型的数据源,而不需要关心底层实现细节。
1. **错误处理机制**
MCP 实现了专门的错误处理机制:
```python
class MCPResponse(BaseModel):
jsonrpc: str = "2.0"
result: Optional[Dict[str, Any]] = None
error: Optional[Dict[str, Any]] = None
id: int
```
这种错误处理不仅包含了错误信息,还可以包含上下文相关的错误详情,帮助 AI 模型更好地理解和处理错误情况。
1. **可扩展性**
从 README.md 中的扩展建议可以看出,MCP 设计考虑了更多 AI 相关的扩展场景:
```markdown
1. 添加更多文件系统操作
2. 实现数据库连接器
3. 添加 API 访问功能
4. 实现缓存机制
5. 添加日志记录
6. 实现安全认证
```
1. **安全性考虑**
MCP 特别考虑了 AI 工具访问系统资源时的安全问题:
- 文件系统访问限制
- 身份验证和授权机制
- 请求验证和输入清理
总结:
MCP 的主要优势在于它是专门为 AI 工具设计的协议,提供了:
1. 统一的数据源访问接口
2. 丰富的上下文信息传递
3. AI 特定的错误处理机制
4. 更好的安全性考虑
5. 专注于 AI 工具的交互需求
这使得它比通用的 HTTP 或 RPC 协议更适合 AI 工具和外部服务之间的通信。虽然底层可能使用 HTTP 或 RPC 作为传输协议,但 MCP 在此基础上添加了专门为 AI 工具设计的抽象层和功能。
___
Chatbot 想要添加联网功能,生成图片等等,现在都要自己写死tools。但是支持了 MCP 之后就不用了。扩展性大大增强。这个未来是个非常大的市场。想象一下,任何 Chatbot 客户端,配置一个 MCP URL 就可以支持任何想要的功能,无需作者开发。现在所有提供 RESTful API 的厂商都可以推出支持的 MCP
就是大模型脑子里有一堆脚本,可以调各个平台的 api 吗,那这是大模型自己的事啊,为啥还需要别的平台支持呢
你的疑问很好,确实值得深入了解一下:
虽然大模型(LLM)本身具备强大的语言理解和代码生成能力,但要真正落地成你刚才看到的那种顺滑体验,光靠大模型自己还不够。
具体原因是:
## 1. **LLM 本身无法直接执行代码**
- 大模型擅长生成代码,但本身并不具备**执行代码的能力**。
- 它只能生成代码片段或程序,但不能直接启动、运行、控制程序。
因此,需要一个额外的『桥梁』——MCP,就是起到这种角色,把大模型的**输出**(代码、命令)实时地**执行**起来,并将**执行结果**再实时返回给模型,从而实现**动态的互动闭环**。
---
## 2. MCP具体负责哪些事情?
通常,MCP会负责:
- **运行时环境**:
- 管理代码执行环境(比如Python运行时、数据库连接、接口调用的权限)。
- **权限与安全控制**:
- 控制模型生成代码的权限、范围、访问API时的鉴权,防止越权或误操作。
- **状态与上下文管理**:
- 记录任务状态,保存脚本运行结果并反馈给LLM,便于后续步骤继续运行。
- **API调用与集成**:
- 提供API调用能力,比如请求外部数据库、服务接口、第三方平台API(如MySQL、Redis、Notion、Slack、Excel、CRM、BI工具等)。
- MCP事先封装好了各个平台API的调用方式,让大模型只需给出意图即可,无需了解API的细节或复杂性。
---
## 3. 为什么LLM不能单独完成这些事情?
LLM的本质是语言模型(只产生文本),不是应用程序运行环境。它没有:
- **代码的执行权限**
- **网络通信能力**
- **状态存储和维护机制**
- **安全与权限管理**
换句话说:
- LLM自己只是个聪明的『大脑』,能想明白"怎么做",但实际操作需要外部的『手脚』执行。
- MCP就是这种外部的手脚,负责对接真实世界中的程序环境、API服务、数据库资源等,真正做事。
---
## 🌟 用一个生动比喻总结
> 大模型(LLM)像是一个『智囊团』或『指挥官』,擅长思考、做决策,但不会亲自动手。
> MCP像是配备的『士兵或工程队』,负责具体动手执行命令。
> 两者协作才能真正高效完成任务。
因此,MCP 这种外部平台的支持对实现真正的交互式自动化和自助服务体验是必不可少的。