[[qlib]]
量化交易(Quantitative Trading)
│
├─ [[时间序列分析]]预测 ← 只是一部分!
├─ 因子模型
├─ 统计套利
├─ 高频交易
├─ [[机器学习$]]
└─ 风险管理
关系:时间序列预测 ⊂ 量化交易
# 为什么做量化?
**总结一下量化的两个好处**
1. 虽然打不过机构,但是可赢过其他随意的散户们
2. 提高纪律性(摆脱情绪控制)和如臂使指的准确性
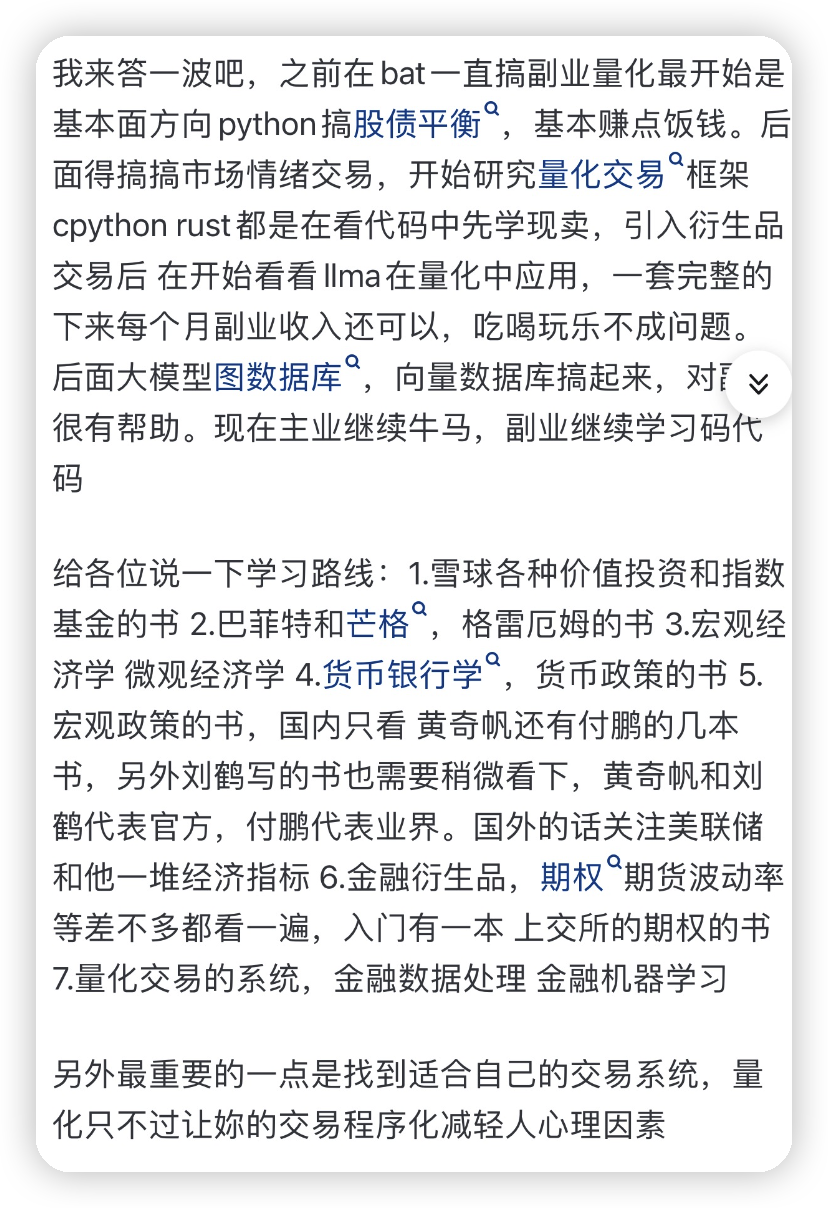
我选择做买方quant的理由如下,绝对主观:1.好奇心。我喜欢玩解谜游戏。做empirical research和解谜很相像。对证据和人性进行分析、思考,寻找关联,做出假设,得到结论,等待验证。真相揭晓的一刻令人兴奋。2.自由。只要策略能获得收益,没有人限制我想研究什么数据,应用什么方法,阅读多少文献,和多少人聊天。3. 有挑战性。预测市场是一件困难的事情。做出一个稳定高收益的投资组合有成就感。4.投资渠道。一个成熟的系统化投资组合,会带来个人资产的稳健增长。天降一个亿,而不知如何投资,也是一件令人头疼的事。5. 学以致用。这是一个可以把科学文化知识直接转化为财富的行业。从前看似无用的理论,在这个行业中都被直接或间接地应用了。6.和优秀的人一起工作。敢于挑战且能战胜市场的人,都很优秀。和他们一起工作,是一件令人享受的事情。7. 个人持续进益。虽然个人做的努力会100%奉献给平台,但也有至少80%加成在自己身上。随着工作年限增长,经验在不断积累,视角会越来越宽阔,技能点也越来越丰满。离开平台的时候,也能自信地应对风浪。综上,毕业以后我加入了quant阵营。
# 路径
一、低成本技术栈搭建
1. 平民级开发环境
- 硬件:二手ThinkPad P系列(配备NVIDIA Quadro显卡)约$800
- 云资源:Google Colab Pro($10/月)+ AWS Spot Instance突发使用
- 数据源:
- 免费:Yahoo Finance + Alpha Vantage(5年历史数据)
- 低成本:TradingView付费版($14.9/月)获取实时数据
- 另类数据:爬取SEC EDGAR系统(Python的Sec-edgar-downloader库)
2. 开源武器库
- 回测框架:Backtrader(支持多资产类别)+ PyAlgoTrade(事件驱动)
- 因子库:TA-Lib(158个技术指标)+ WorldQuant的alpha101公式复现
- 机器学习:Fast.ai(简化版深度学习)+ SHAP值归因分析
二、微型策略开发路线
1. 首月生存策略
- 期限套利:加密货币跨交易所价差捕捉(Binance vs FTX遗留市场)
- 工具:CCXT库连接20+交易所API,用Pandas计算瞬时价差
- 风险控制:自动止盈止损(Talib的ATR指标动态调整)
2. 三月进阶策略
- 统计套利:A股ETF配对交易(华泰证券万得API免费版)
- 步骤:
1. 用Cointegration方法筛选ETF组合
2. 布林带通道设定交易阈值
3. 动态仓位管理(凯利公式改良版)
- 回测工具:JoinQuant模拟盘(10万虚拟本金)
3. 半年突破策略
- 期权波动率交易:VIX期货期限结构套利
- 数据:CBOE免费历史波动率数据
- 核心算法:GARCH(1,1)模型预测波动率曲面
- 执行:TDAmeritrade Thinkorswim平台(支持Paper Money模拟)
三、实战资金运作方案
1. 启动资金获取
- 竞赛奖金:Kaggle量化赛(Top10团队奖$5000+)
- 外包接单:Upwork上承接量化策略开发(时薪$30起)
- 模拟盘验证:在QuantConnect社区发布策略,吸引跟投分成
2. 微型账户管理
- 初始规模:$1000-5000(建议从加密货币入手)
- 资金分配:
- 70%主策略(日频交易)
- 20%对冲策略(期权保护)
- 10%高风险套利(跨市场搬砖)
- 出金纪律:每月盈利超20%部分强制转出至冷钱包
四、能力证明体系构建
1. 可视化成果展示
- 动态简历:用Plotly Dash搭建交互式策略演示平台
- 策略图谱:Neo4j数据库展示因子关联网络
- 代码证书:GitHub仓库+ Quantopian证书(即使平台关闭仍可展示)
2. 非学历认证路径
- Coursera专项课程:密歇根大学《Python金融应用》
- 考试认证:CMT一级(技术分析协会)+ Python Institute的PCAP
- 论文替代:在arXiv发布《零售投资者量化实践方法论》
五、渐进式职业过渡
1. 人脉破冰策略
- Meetup参与:寻找本地Quant Trading Meetup(平均参加成本$10/次)
- 逆向猎头:在LinkedIn主动联系HFT公司初级开发人员
- 内容输出:在Medium发布《DIY Quant》系列文章(每周2篇)
2. 曲线入职路径
- 先入金融科技:从TradingView插件开发者做起
- 转型做数据标注:为对冲基金清洗另类数据(时薪$25)
- 加入DAO组织:参与Quantopian遗产社区复兴项目
六、AI协同切入点
1. 低门槛结合场景
- 自动因子生成:用Codex生成伪代码,人工优化
- 另类数据处理:Stable Diffusion生成模拟订单流数据
- 策略参数优化:PyTorch实现贝叶斯超参搜索
2. 现金流转化设计
- 开发Telegram交易信号Bot(订阅制$9.9/月)
- 出售策略模板:在Gumroad上架MT4/MT5策略包($49/套)
- 建立Youtube频道:量化教学+实时交易展示(联盟营销变现)
七、风险管理手册
1. 熔断机制
- 单日最大亏损:总资金2%(用TradingView警报触发)
- 策略失效指标:夏普比率连续3周<1
- 强制休市规则:连续3笔亏损立即停止交易1周
2. 生存保障线
- 保留现有主业收入50%以上
- 建立6个月生活费的USDC储备
- 购买商业保险:专业责任险(年费$500保额$100万)
关键成长指标:
- 第1年目标:开发3个盈利策略,管理资金达$10k
- 第2年目标:年化收益超30%,启动AI数据标注业务
- 第3年目标:建立自动化交易系统,申请新加坡MAS牌照
这个路径的精髓在于:用开源工具降低技术门槛,用竞赛和外包解决资金问题,用内容输出构建个人品牌,最终通过可验证的交易记录突破学历限制。建议从今天开始建立交易日志,记录每个策略的盈亏比、最大回撤等核心指标,这是未来说服机构投资者的关键凭证。
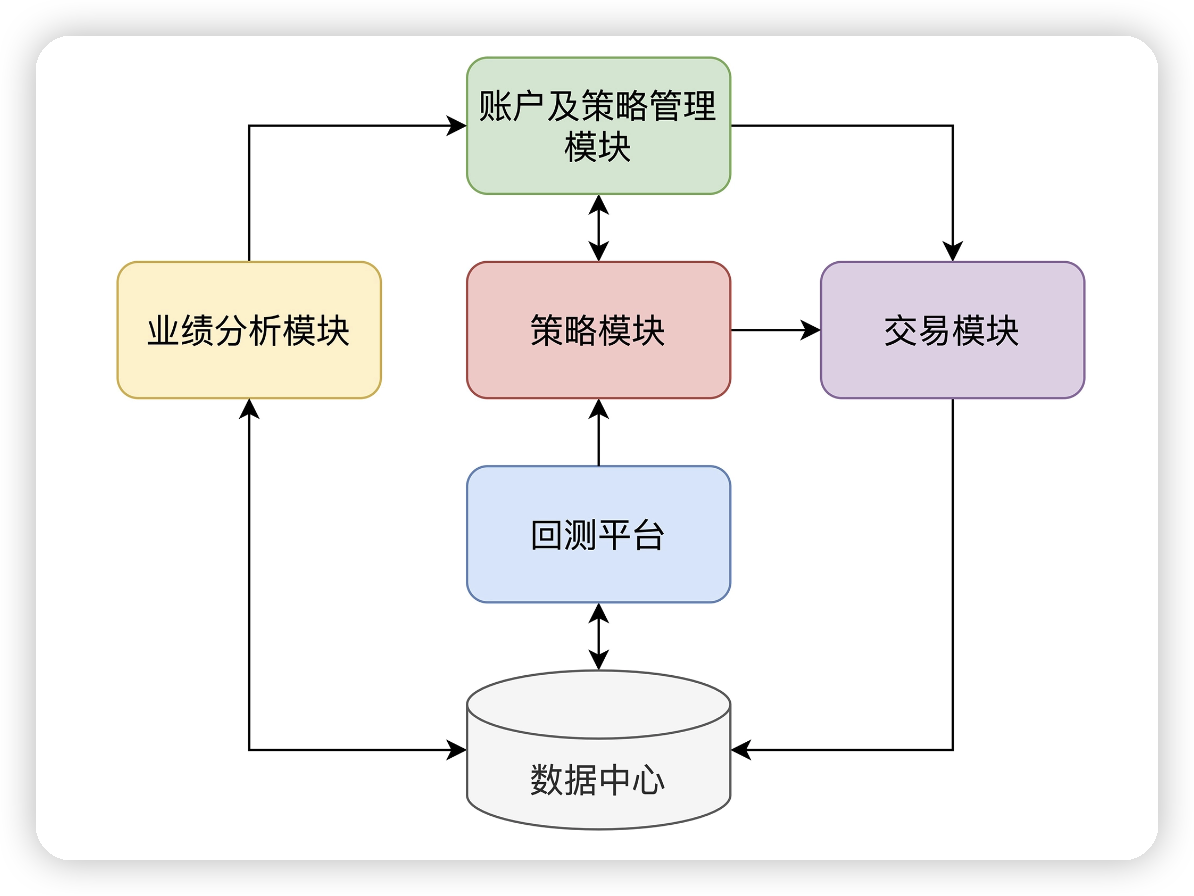
# 架构
# 数据

根据您提供的市场数据订阅选项列表,我建议您考虑以下几个选项:
1. Cboe One(非专业,一级)- USD 1.00/月
这个选项提供来自四家CBOE美国股票交易所的实时串流报价,覆盖范围较广,价格也很合理。
2. 纳斯达克(Network C/UTP)(非专业,一级)- USD 1.50/月
提供纳斯达克挂牌证券的实时数据买/卖报价,包括许多知名科技股。
3. 纽交所(Network A/CTA)(非专业,一级)- USD 1.50/月
提供纽交所挂牌股票的实时市场数据,包括许多蓝筹股。
4. 纽交所美国证券交易所、BATS、ARCA、IEX与区域性交易所(Network B)(非专业,一级)- USD 1.50/月
这个选项涵盖了许多其他重要的交易所和平台。
5. OPRA(美国的期权交易所)(非专业,一级)- USD 1.50/月
如果您对期权交易感兴趣,这个选项很有价值。
这些选项合计每月费用为7美元,可以为您提供全面的美国股票和ETF市场数据覆盖。如果您主要关注特定类型的证券,可以根据需求选择其中的一部分。
另外,美国共同基金(非专业,一级)是免费的,如果您对共同基金感兴趣,可以考虑添加这个选项。
最后,根据您之前提到的CHAU股票,它很可能属于纽交所ARCA交易的ETF,所以"纽交所美国证券交易所、BATS、ARCA、IEX与区域性交易所(Network B)"这个选项可能是最直接相关的。
您可以根据自己的交易需求和预算来选择最适合的组合。如果您有特定的交易策略或关注的市场板块,也可以告诉我,我可以进一步为您提供建议。
## 策略模块
| 策略类别 | 描述 | 示例 |
|----------|------|------|
| 投资想法类 | 由一个简单的投资想法生成的策略 | 基于日历效应的策略 |
| 因子驱动类 | 由一些有价值的因子驱动的策略 | 技术面:动量因子、反转因子<br>基本面:估值因子、成长性因子 |
| 交易策略类 | 由经典的策略思想细化而来的策略 | 配对交易、趋势跟踪等 |
| 交易模型类 | 更加复杂的策略,程序员擅长的领域 | 机器学习、深度学习的模型 |
| | | |
| ----- | --------------------------------------- | ------------------------------------- |
| 多因子模型 | 概念:建立在定量的学术基础上,是把多个因子整合在一起,来获出最大作用的投资模型 | |
| | 巴菲特化投资中最重要的模型 | 葛格熟悉使用多因子模型,是区分量化投资高手和初学者的重要分界线 |
| | | 多因子模型是量化投资的一些基础心思想 |
| | 股票预测中的常用因子 | 宏观因子 |
| | | 行业因子 |
| | | 技术面因子 |
| | | 基本面因子 |
| | | 大数据因子 |
| | 线性多因子模型的数学形式 | r = f1 * X1 + f2 * X2 +... + fK * XK |
| | 如何用多因子模型做投资管理 | 分清主次,给不同因子不同权重 |
| 机器学习 | 用机器学习建立投资模型 | 流程:样本生成、特征选取、模型训练、测试验证 |
| | 以预测股票涨跌为例 | 训练数据是通过历史数据计算得出的 |
| | | 在生成过程中要剔除引入未来信息 |
| | 解决趋势相关的预测问题 | LSTM、RNN |
| | 基于处理特征工程的问题 | [[XGboost]]、[[DeepFM]] |
| | 细节的数据清洗 | |
| | 精准的问题定义 | |
| | 机器学习模型也有局限性 | 避免生产者的过拟合投资 |
| | | 黑盒特征 |
| | | 金融数据的强噪声性 |
这是啥
这里推荐一个我最开始学习量化到现在依然在追的 github仓库,他就是awesome-quant,里面包含了编程、回测、因子框架、资产定价、交易、风险定价等等你所需要的量化知识。在github上有15.7k的 star,受到广大量化爱好者和业界人士的喜爱。这里我简单截取了几个部分:p1:仓库介绍 p2:金融工具定价 p3:交易回测 p4:回测&ai等 p5:因子分析、世间序列
最后感觉现在很多人在神话量化,但是在我看来量化投资没那么高深,跟主观投资一样只是一种投资理念与方式,跟你看k线、搞产业链没有高低贵贱之分,大家一定要祛魅。我喜欢量化是因为他可以帮助我客观理性的看待这个市场,甚至这个世界。人性、逻辑、情绪、情感、风格等等都可以运用统计学和数学方式量化出来,这本身就是一件有乐趣的事情,虽然很有可能研究了几个星期发现鸟用没有。最后祝每一位热爱量化的小伙伴都能找到属于自己的alpha 6o
[GitHub - thuquant/awesome-quant: 中国的Quant相关资源索引](https://github.com/thuquant/awesome-quant)
[GitHub - wilsonfreitas/awesome-quant: A curated list of insanely awesome libraries, packages and resources for Quants (Quantitative Finance)](https://github.com/wilsonfreitas/awesome-quant)
相关公司:
[佳期投资](佳期投资.md)
[九坤投资](九坤投资)
## Step 1. 提取与审查——文本主旨与隐性前提
**简要复述**
1. **主力策略极简却最赚钱**:一家量化机构真正赚钱的往往是 3–5 个非常简单的“老”策略(均线、一元线性回归之类),占用 80 % 以上资金并贡献主要利润。
2. **“长尾”策略多而不赚**:其余几十个策略(特别是新来的研究员做的 ML 策略)整体可能不赚钱。
3. **为什么仍要招 quant / 搞 ML**
- _对外讲故事_:向投资人或上级展示“高科技”“大团队”以获取资金或KPI。
- _对内分工_:让员工承担洗数据、盯盘、调参等苦活,同时保持“做高端研究”的职业期待。
4. **机器学习≠盈利来源**:真正决定盈亏的是因子本身;因子若赚钱,用不用 ML 差别不大。
5. **ML 难点**:金融价格序列信噪比低、样本量有限→易过拟合;高频虽数据多却受滑点与容量限制。
6. **结论**:在国内大部分量化私募里,ML 主要价值是“故事”而非“收益”。
**隐性前提与局限**
|隐性假设|可能局限或风险|
|---|---|
|① 市场中“极简策略”长期可持续并能容纳大额资金|未讨论策略衰退与规模变动的生存性检验;忽视择时失效风险|
|② 金融数据**天然**低信噪且样本少 → ML 无用|忽视替代数据源(卫星图像、文本、订单簿深度)与特征工程可显著提高信噪比的事实|
|③ ML 只能做信号预测|未考虑 ML 在组合优化、风控、成交算法、自动化监控等环节的价值|
|④ “讲故事”一定比“真实收益”更能吸引资金|对部分机构/资管人群的尽调深度和绩效追踪要求估计不足|
|⑤ 员工只为薪水或学习机会而接受低效研发|忽视人才流动与知识泄露导致的护城河侵蚀|
---
## Step 2. 显性揭示盲点——作者可能遗漏的关键要素
1. **跨资产 & 横截面 ML 证据**
- 大样本横截面(数千股票 × 数百特征)显著缓解样本不足;多项研究表明非线性 ML 方法能在风险调整后超越线性基准。
2. **另类数据与噪声降维技术**
- 订单簿、新闻、卫星图像、ESG 文本等数据已被用来提高信号质量;扩散模型去噪、表征学习不断演进。
3. **Risk-Tech 价值链**
- ML 在波动率曲面插值、极端风险预测、交易成本建模、智能执行(SOR / RL 执行代理)中的商业落地被低估。
4. **国际监管与信息披露压力**
- 美欧监管机构要求对 AI/ML 模型做解释、压力测试,限制“只讲故事”而缺少可审计流程。
5. **复合策略与元学习**
- 近年流行的 **ensemble stacking、meta-learning** 可将数十个弱预测器组合成稳健策略,而非简单地“多添几个不赚钱的 ML 模型”。
6. **人力资本与知识产权风险**
- 过度依赖“苦力型”量化团队导致人才流失,且流程文档化不足时,核心策略难以在组织层面沉淀。
---
## Step 3. 权威参照与对比
|主题|文本主张|全球/学术共识或对立证据|评价|
|---|---|---|---|
|ML 对股票预期收益的贡献|基本无增益|Gu、Kelly & Xiu (2020) 发现随机森林/神经网络在横截面预测上**经济收益翻倍**,因捕获非线性交互 ([Empirical Asset Pricing via Machine Learning - Oxford Academic](https://academic.oup.com/rfs/article/33/5/2223/5758276?utm_source=chatgpt.com))|存在显著分歧|
|ML 改善因子预报|“同样因子换模型没意义”|AlphaArchitect (2024) 亦指出 ML 提升有限 ([Can Machine Learning Improve Factor Returns? Not Really](https://alphaarchitect.com/2024/04/can-machine-learning-improve-factor-returns-not-really/?utm_source=chatgpt.com))|业界学术仍有争论;效果依赖数据宽度与调参|
|数据低信噪 → 过拟合|赞同|芝大 BFI《Can Machines Learn Weak Signals?》证明低 SNR 环境下算法易失效 ([[PDF] Can Machines Learn Weak Signals?](https://bfi.uchicago.edu/wp-content/uploads/2024/03/BFI_WP_2024-29.pdf?utm_source=chatgpt.com))|观点一致|
|机构使用 ML 的真实目的|“讲故事”占主|2024 美参议院报告称部分对冲基金披露不足、存在监管担忧 ([[PDF] 2024.06.11-Hedge-Fund-Use-of-AI-Report.pdf](https://www.hsgac.senate.gov/wp-content/uploads/2024.06.11-Hedge-Fund-Use-of-AI-Report.pdf?utm_source=chatgpt.com))|有一定佐证,亦提醒风险控制需求|
|高频 ML 受容量限制|赞同|HFT 研究强调滑点与成本对 RL/HFT 模型盈利影响显著 ([[PDF] Impact of Machine Learning on High Frequency Trading](https://ijsret.com/wp-content/uploads/2024/11/IJSRET_V10_issue6_571.pdf?utm_source=chatgpt.com))|观点一致|
|ML 适合非金融场景|赞同|文献综述指商业/图像领域 SNR 高,ML 效果最佳 ([Machine learning in business and finance: a literature review and ...](https://jfin-swufe.springeropen.com/articles/10.1186/s40854-024-00629-z?utm_source=chatgpt.com))|观点一致|
---
## Step 4. 认知更新建议
1. **区分场景与任务**
- 将 ML 价值拆分为 _信号预测_、_交易执行_、_风险管理_、_流程自动化_ 四条链路,逐一评估边际贡献。
2. **引入替代数据 + 特征学习**
- 结合文本情绪、卫星夜光、订单簿微结构,并采用自监督/扩散去噪提升信噪比;再与传统因子叠加做 **hybrid alpha**。
3. **采用严谨的“先经济后统计”框架**
- 以 **经济假设 → 特征工程 → 交易成本模型 → walk-forward 验证** 的闭环来约束过拟合,而非盲目网格调参。
4. **关注模型治理与解释性**
- 按监管趋势建立模型文档、追踪误差、压力测试与 _model lineage_;防范“讲故事”带来的合规风险。
5. **人才激励与知识沉淀**
- 通过 **profit-sharing + 技术分享会 + 自动化工具链**,让研究员既能承担数据运营也能真正迭代核心因子,减少“苦力-镀金”落差。
6. **量化“容量–复杂度”前沿**
- 用 **稳健的冲击成本曲线** 衡量策略可承载资金;对高频/非线性策略先做微观容量分析,再决定是否值得 ML 投入。
---
## 概念树(Concept Tree)
- **量化机构盈利结构**
- 主力极简策略
- 高资金占用
- 历史悠久
- 长尾多样策略
- 多为 ML / 新人研发
- 总体收益低
- **隐性假设**
- 简单策略可长期扩容
- 低信噪→ML 无效
- ML 仅用于预测
- **盲点**
- 替代数据与降噪
- ML 在执行 / 风控价值
- 监管与模型治理
- 组织知识与人才流动
- **权威参照**
- 正面证据:Gu-Kelly-Xiu、HFT 研究
- 负面证据:AlphaArchitect、参议院报告
- **改进建议**
- 分模块评估 ML 价值
- 引入多源数据 + 去噪
- 建立经济假设驱动的验证框架
- 加强模型可解释性与合规
- 设立人才与知识沉淀机制
- 量化容量–复杂度权衡
这棵概念树串联了文本论断、隐性前提、缺失要素、外部证据与更新路径,帮助你在后续研究与实践中快速定位关键议题并进行深挖。