viva 的数据可视化可以参考 B 站的流量占比分析
探索 AI 对于个人开发者的赋能
[CICD for viva](CICD%20for%20viva.md)
# 商业化
**国内的*高阶*英语学习是没有全链路数字化的管理系统的**
# 愿景
**我想做的是英语世界的溯源系统**
还是软件开发中数字化+智能化的方式
网站本身首先是一个传感器,将过去白白流逝掉的英语使用信息数字化保存
其次是一个算法平台,从数据中挖掘规律,找到学习中最痒的那个点,反馈用户
# 音频模块
可以参考
[[dejavu$]]
https://x.com/sekay2016/status/1913208943503131040?s=46
# 设计思想
## 什么是英语能力
英语的本质是四个 Map的[[词汇量]],每种 Entry 的数量决定了能力
四级小王
听词量:100
说词量:20
读词量+:5000
写词量+:500
德州农民
听词量:10000
说词量:5000
读词量:1000
写词量:500
一般人在背单词时,如果5秒内想不出词义,就把这个单词归为生词了。几秒是一般人对一个单词的反应时间,实际上这远远不够。一般的英文语速是150词/分钟,平均一个单词只有60/150=0.4 秒的反应时间。这个速度一闪而过,根本来不及想。所以,如果一个单词从来没有在你听过的句子中出现过很多次,你几乎无法反应过来,即使你背过了。
| | | | | | | | |
| -------------------- | ---- | ------------ | ---------- | -------- | -------- | --- | --- |
| 四种 Map | 类型 | 作用 | 3000 Entry | 5000 | 8000 | | |
| Map<Symbol,Thought> | 阅读词汇 | 看到单词 → 理解含义 | 高考水平 | 六级 500 分 | 雅思阅读 7.0 | | |
| Map<Audio,Thought> | 听力词汇 | 听到声音 → 理解含义 | 六级 500 分 | 六级 600 分 | | | |
| Map<Thought,Sound> | 口语词汇 | 想表达含义 → 说出声音 | 雅思口语 6.5 | 雅思口语 7.5 | | | |
| Map<Thought, Symbol> | 写作词汇 | 想表达含义 → 写出单词 | 雅思写作 6.5 | 雅思写作 7.0 | | | |

[音标](音标.md)和[英语语法](英语语法.md)是两个非常小的模块
主要的工作量在于[被动词汇](被动词汇)和[主动词汇](主动词汇.md)的积累
听力和阅读是被动型映射,听力是上限,阅读是下限。能听出来的基本都可以认出(在掌握音标的前提下)。
写作和口语是主动型映射,写作是上限,口语是下限。能写出来的基本都会说(在掌握音标的前提下)。
SortedMap<Thought,Expression>,sorted by 词频+场景 这样效率最高
1. 找老外,聊 30 分钟
2. 复盘 90 分钟,Thought,Expression
3. review
## 解决痛点
1. 主动词汇:基于中文上下文的精准中译英的主动词汇寻找,并按照英文语序呈现
2. 被动词汇:基于兴趣内容生成播客音频
3. 间隔复习、精听
# 几大模块
## 主动词汇模块
1. 用户上传中文文章
2. 中文文章分成『中文句卡』
3. 中文句卡翻译成英文句子
4. 按照英文语序找到每个对应的中文
5. 根据 wordNet 做拓展(让 AI 选择最符合的意群,拿到实际的可替换同义词)
## 进度和复盘模块
1. Anki 里的 supermo 算法
2. 根据用户的词频积累对照 COCA 语料库得到进度
3. 根据用户的语法使用对照 general 的英语语法现象得到进度
4. 找到主动词汇和被动词汇的 gap 部分
## 被动词汇模块
阅读:见过的词 > 要背的词 > 已掌握的被动词汇
听力:见过的词 > 要背的词 > 已掌握的被动词汇
1. [[viva浏览器插件]]
2. 根据用户的所有中文文章和英文翻译生成播客(google 接口)
3. 播客精听
⚠️ **重点思想**
1. **词典主数据** 与 **用户学习进度** 解耦。
2. **词书/课程** 通过「中间表」灵活组合。
3. **Spaced Repetition** 用 `review_state` 表存储算法参数,保证查询&更新都在单表完成。
4. 日志、统计、打卡等写入「宽表」或「分区表」,避免高频读写与核心查询互相干扰。
###
可以参考 github 的 insights 获取灵感

# 待开发模块
1. **CICD**
2. 间隔复习模块supermo
1. 前端 kaggle+小红书
2. 后端
3. **已有性能优化**
4. **观测性和复盘模块**
5. **内容生成播客模块,被动模块**
6. **前端**
# 会员体系
1. 免费用户能获得基础的主动词汇的服务(DeepSeek 的 API 很便宜,每人加个限额即可控制成本)
2. 付费用户可以选用更好的 AI 基座,解锁更多的模块(比如复盘模块)
# 服务器
___
**通过两三年的努力,终于能把问题和需求定清楚,这样占了我之前那个想法,后代产品的核心竞争力就在于他能够提出需求,相比之下实现需求反而变得简单**
最终的目的是在英语这个一切有解,一切能具体到生活的,理想的,学习试验田上,实现学习过程的数字化,找到学习中最痒的那个点,实现有效积累,快速进步,降低总的时间成本。
- 抖音、小红书能利用算法挖掘自媒体内容中的优点、卖点,同时激发新的内容创作。我们为什么不能数字化我们和世界的交互过程,并利用算法挖掘和作用呢?
- 好的产品,应该帮助用户回归本真,回到第一性原理最能发挥的动作中,并让其低成本重复
英语相比其他学科的知识图谱来说已经是一个结构最简单的图结构了
# 主要思想
对英语的掌握,本质是脑中四种映射的数量。
```mermaid
graph TD
A((英语学习)) --> B[被动映射]
A --> C[主动映射]
B --> D[听力词汇量]
B --> E[阅读词汇量]
C --> T[想法]
T --> H[表达(单词或短语)]
H --> F[口头版本——声音]
H --> G[书面版本——拼写]
style H fill:#bbf,stroke:#333,stroke-width:4px;
style T fill:#bbf,stroke:#333,stroke-width:4px;
```
| | | |
| ---- | -------------- | ----------------------------------------------------------------------------------- |
| 主动映射 | active_mapping | 我想『打』死你 -> beat<br>给我一『打』鸡蛋 -> dosen |
| 想法 | thought | 是主动映射的 key,由 sentence 和 句子中的聚焦位置 focus_word 共同组成,这样就能精确定位出一个想法,比如:我想『打』死你,给我一『打』鸡蛋。|
| 表达 | expression | 是主动映射的 value的 object,包括『口头版本』written_expression『书面版本』oral_expression |
| | | |
# 写作部分,通过 essay 增加 mapping 数量
```mermaid
graph LR
E[essay] --> |分词| A
A[active_mapping_list] --> m1[mapping1]
A --> m2[mapping2]
A --> m3[mapping3]
A --> mn[mapping ……]
```
| | | |
| ------ | --------------- | ---------------------------------------- |
| 文章 | essay | 是用户输入,是念头的集合 |
| 用户的表达 | user_expression | |
| AI 的建议 | ai_review | 包括 is_correct 和 ai_expression |
| 映射卡片 | mapping_card | 包括 thought,user_expression,ai_expression |
## 做题
| | 流程 | |
| --- | ------------------------------------------- | --- |
| | 上传 essay | |
| | 中文分词,获得 active_mapping_list,返回 mapping_card | |
| | 用户在 sentence_card 中填写 mapping_card | |
| | ai 检查 mapping_card | |
| | 用户添加需要间隔复习的 mapping_card | |


## 错题本
```mermaid
graph LR
C[mapping_card] --> D[做题阶段]
D --> d1[1. 填入自认为的表达]
D --> d2[2. AI review]
D --> d3[3. 加入错题本]
C --> A[错题本阶段]
A --> e1[1. 正面看到 thought、之前的错误表达]
A --> e2[2. 填入自认为的表达]
A --> e3[3. 和正确答案对照]
```
---
[口语课复盘 demo](口语课复盘%20demo.md)
[Streamlit](Streamlit.md)
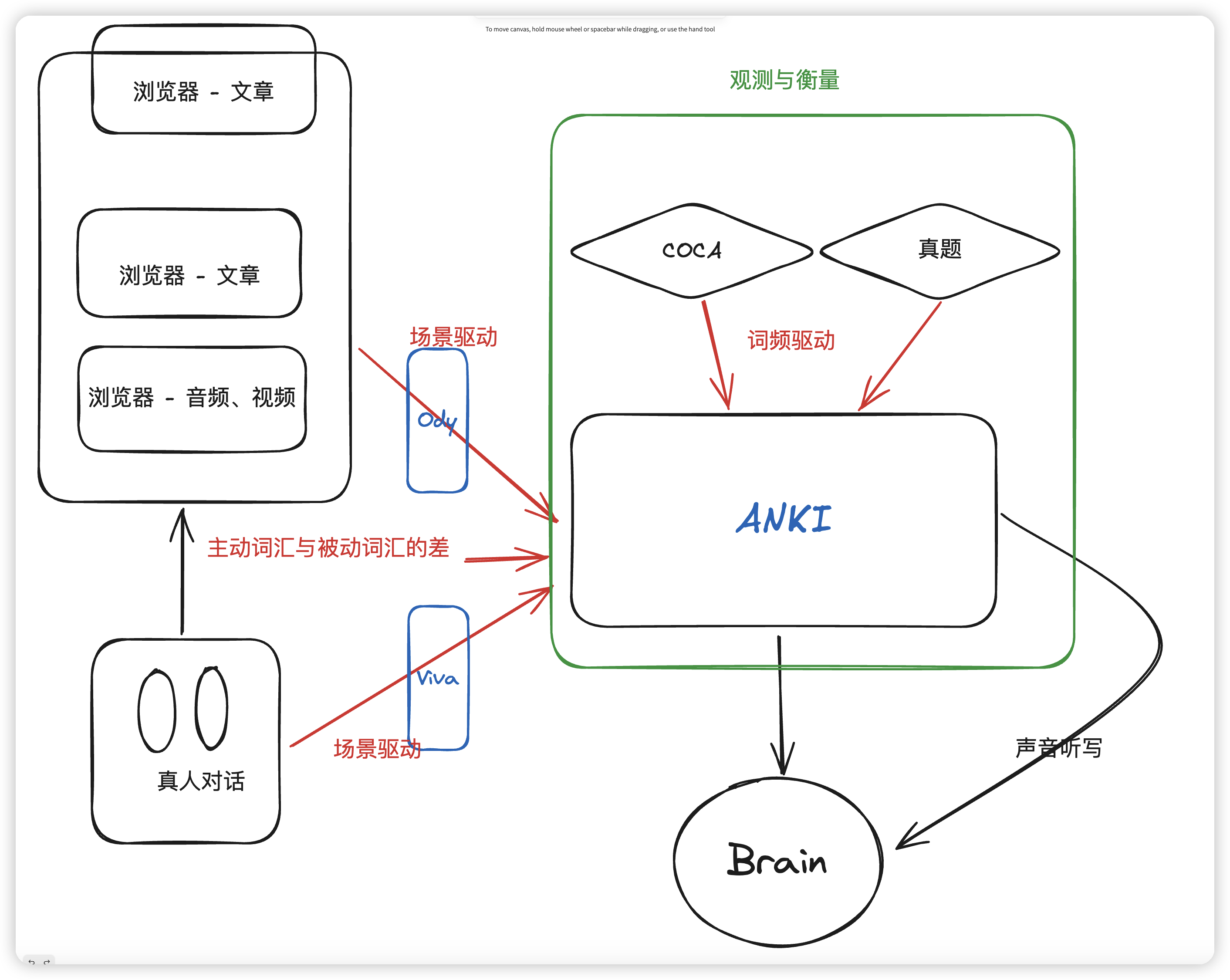
```mermaid
graph TD
subgraph Browser["浏览器"]
B1["文章"]
B2["文章"]
B3["音频、视频"]
end
subgraph Observation["观测与衡量"]
O1["COCA"]
O2["真题"]
end
A[ANKI]
Brain["Brain"]
R["真人对话"]
B1 -->|场景驱动| A
B2 -->|场景驱动| A
B3 -->|场景驱动| A
R -->|场景驱动| A
O1 -->|词频驱动| A
O2 -->|词频驱动| A
Browser -->|主动词汇与被动词汇的差| A
A --> Brain
Brain -->|声音听写| A
classDef default fill:#f9f,stroke:#333,stroke-width:2px;
classDef observation fill:#bfb,stroke:#333,stroke-width:2px;
class O1,O2 observation;
style A fill:#bbf,stroke:#333,stroke-width:4px;
style Brain fill:#fbb,stroke:#333,stroke-width:4px;
```
# 过去的痛点
1. 自己无法控制复习强度,要么记不牢,要么记忆负担过大,
1. 通过自定义间隔复习的参数可以解决
2. 出现的同义词无法纵览、辨析、比较记忆
1. 通过自己 select 数据可以解决
3. 无法与口语课的数据联动
4. 本质是因为数据不在我们自己的手里
## 功能
### 利用 Anki 实现间隔复习
- 卡片正面
- 该单词用 ChatGPT 生成的中文例句
- 卡片背面
1. 单词的拼写
2. 单词的发音
- 用 11labs 生成的自己的声音模型
### 一键同步到 excel
excel 与 anki 的公用主键应该是单词的拼写
将 excel 作为同义词、例句用法、聚类整理的地方
同时将 anki 记忆数据定期 attach 到 excel
- anki connect 取出单词数据
- 将关心的字段增量更新到 excel 表格
### 一键聚类
- telegram 中 /cluster 触发
- 复习的时候对于脑中无法正确定位的同义词打 flag1
- Anki-Connect 找到 flag1 的单词
- GPT 做聚类分析
## 一键生成 instruction
将外教课的 url 传给 bot,返回 instruction 的 txt 文件
可以用 txt 文件让 chatgpt 生成复习 json
## Vault 内近义词检索
### 一键同步口语课数据
- 上传口语课视频
- 得到复盘内容的同时
- 将本次口语课自己的单词使用情况累计到词库数据上
## 需要的工具
### 从墨墨导出数据
- app 端加入收藏
- 网页端云词库复制出来
### Anki 的原理和使用
### Python
- Telegram Bot 开发
- elevenlabs、openai 的接口调用
- Anki connect 实现 Anki 数据的可编程
- 主被动词汇的差导入 anki 时打上特殊 tag
- 同义词辨析的 api 换成 gemini 的
- viva 改成 stream 似乎能实现补全完整格式的 json
- 每周是不是可以搞一个爽读时间
- 每天执行一次定时任务,把同义词加成标签
- 做一个同步机制,使得 anki 的数据能同步更新到 excel 的 vault 数据库
- 对比 geminipro 和 gpt 的复盘效果
- 将近义词辨析改成 stream 输出
- 写作的复盘也可以检索自己 vault 的近义词做辨析
- Anki 中真正要记的东西一定 要满足一个非常高的阈值,比如这次的 activities 和 programs,不然就会陷入无意义的记忆中。可能半个小时的课,找到十张卡片就已经横多了,更多的时间放到夺取接触老外,多交流本身上
- 复盘的 json 结果中 speaker A 和 B 有些地方标注不对,可能并没有真正生效
- 红色 flag 的单词们能否做近义词分析,然后分组进行辨析
- 看能否利用一些接口,比如 ankiconnect 直接拿到对应的数据,然后分组,使整个过程一件触发,这样就随时可以整理学习了
- 这些接口对于其他的数据分析也很有意义,不然只能从 browse 里面手动复制了,难以实现自动化
- `去重按钮`,找到重复单词的卡片
- `聚类按钮`,一键将混淆词汇聚类,辨析记忆
- 将 chatgpt 矫正的句子的语音加入到原外教课视频中
- 对于极端顽固单词用 sora 生成一分钟的场景视频
先做一个统计累积次频的输入输出
输出仍旧可以是词频建议
用 es 存储和检索?
推荐的可以宽松一些,比如一百个
职责链模式实现视频复盘的处理过程
引入 Jacoco 做代码覆盖率
canva aj
vpc-subnet 内互通是靠 icmp?
## 测试一下各种 parser 的自动注入是真的还是假的
gitaction
总的单词库
每部电影的字幕文件的搜索
## 阐述英语思想的文章里,可以加入已知的未知和未知的未知的概念对比,阐述英语学习的意义
可能需要三轮才能完整获取
- 等大成之后,当一个英语教头?只提供课程资源链接、方法、工具,客单价高,但随时支持按照进度退款?
- 和健身房一样,赚坚持不下去的人的钱