<!-- more -->
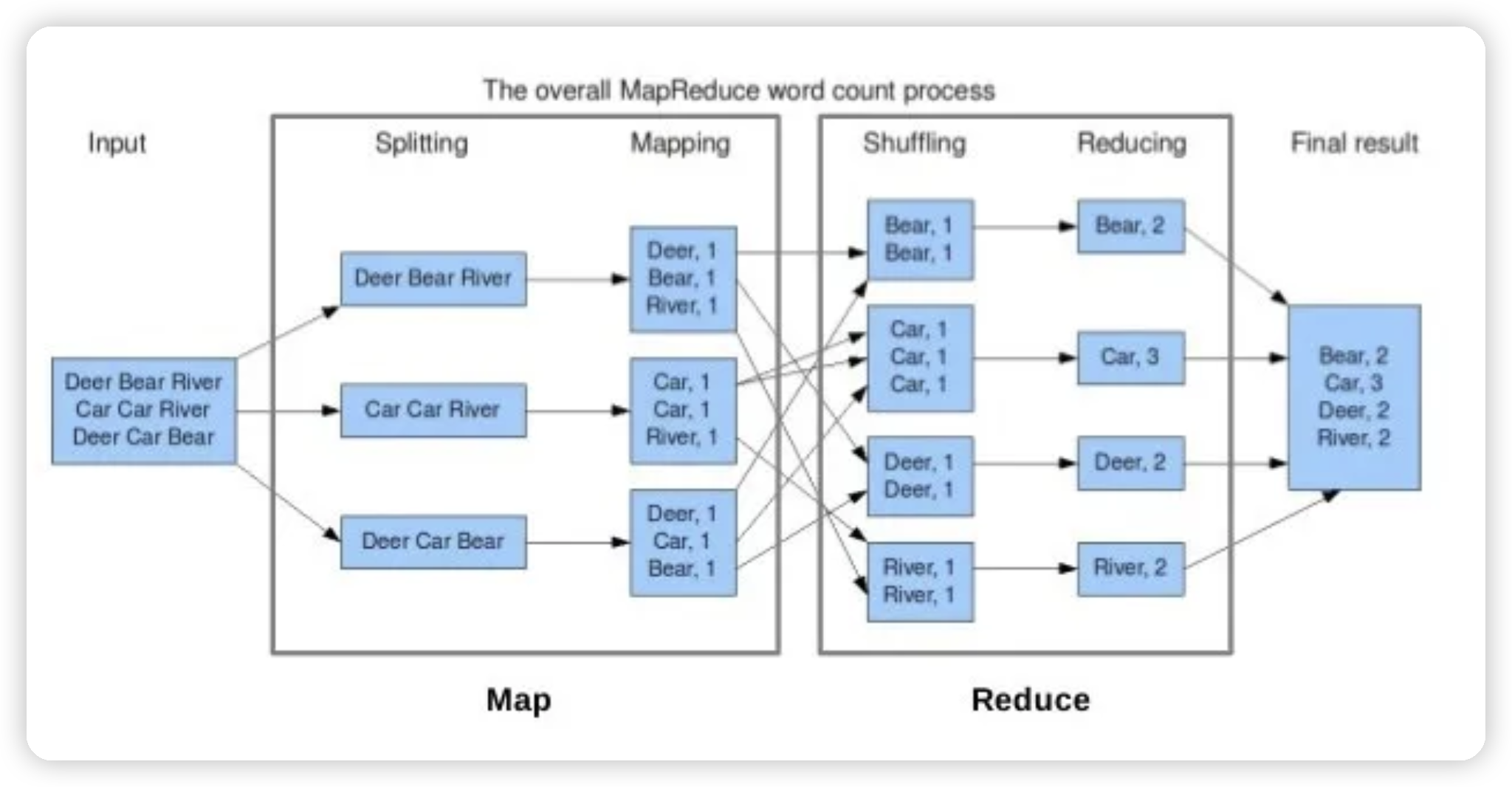
以统计一段长文本的各单词词频为例
1. split 任意切分原始输入——总的大文本是可以任意分割的
2. map 无依赖的计算——逐个统计就好,是无状态的
3. Shuffle 整理牌,把相同 key 的放一起
4. reduce 有依赖的计算——按照同一个单词作为 key 进行规约
5. MR 容错—矩阵(包括数据)

1、内存和磁盘使用方面 [Spark](Spark.md) vs MapReduce 不等于内存 vs 磁盘,Spark 和 MapReduce 的计算都发生在内存中,区别在于:•MapReduce 需要将每次计算的结果写入磁盘,然后再从磁盘读取数据,从而导致了频繁的磁盘 10。•Spark 通常不需要将计算的结果写入磁盘,可以在内存中进行迭代计算 Q。这得益于 Spark 的 RDD 和 DAG(有向无环图 Q),其中 DAG 记录了 job 的 stage 以及在 job 执行过程中父 RDD 和子 RDD 之间的依赖关系。中间结果能够以 RDD 的形式存放在内存中,极大减少了磁盘 I0Q。
2、Shuffle 上的不同 Spark 和 MapReduce 在计算过程中通常都不可避免的会进行 Shuffle,Shuffle 都会落盘,但:• MapReduce 在 Shuffle 时需要花费大量时间进行排序,排序在 MapReduce 的 Shuffle 中似乎是不可避免的;• Spark 在 Shuffle 时则只有部分场景才需要排序,支持基于 Hash 的分布式聚合,更加省时;
## 特性
MapReduce的核心在于其任务的可分性和可规约性:
1. **可分性**:问题可以被分解为多个独立的子任务。
2. **可规约性**:这些子任务的结果可以被合并得到最终结果。
## 那么反面是啥,什么任务是不可规约的?
反过来说,不适合MapReduce的任务通常具有以下特征:
1. **强依赖性**:任务中的步骤彼此强烈依赖,无法并行处理。
2. **顺序性**:必须按特定顺序执行的任务。
3. **全局状态依赖**:需要访问或修改全局状态的任务。
4. **迭代性**:需要多次迭代的算法,每次迭代依赖于前一次的结果。
5. **实时性要求**:需要快速响应的实时或近实时处理任务。
6. **小数据量**:数据量较小,分布式处理的开销可能超过其带来的收益。
7. **复杂的数据关系**:涉及复杂的数据关系或图结构的任务。
## 具体例子
1. **图算法**:如PageRank,需要多次迭代且每个节点依赖于其他节点的状态。
2. **机器学习算法**:许多机器学习算法需要多次迭代和全局状态。
3. **事务处理**:需要保持全局一致性的数据库事务。
4. **自然语言处理**:某些NLP任务需要考虑整个文本的上下文。
5. **实时流处理**:需要立即处理和响应的数据流。
## 结论
虽然MapReduce强大且适用于许多大数据处理场景,但它并非万能的。对于具有强依赖性、顺序性、全局状态需求或迭代性的任务,可能需要考虑其他分布式计算模型,如图计算框架(如Pregel)、流处理系统(如Apache Flink)或更通用的分布式计算框架(如Apache Spark)。