# Plan
1. 理解技术侧的原理、框架
2. 理解互联网公司的数据基建
3. 理解[[数据分析师]]的技能栈
好的,我来加上使用场景说明:
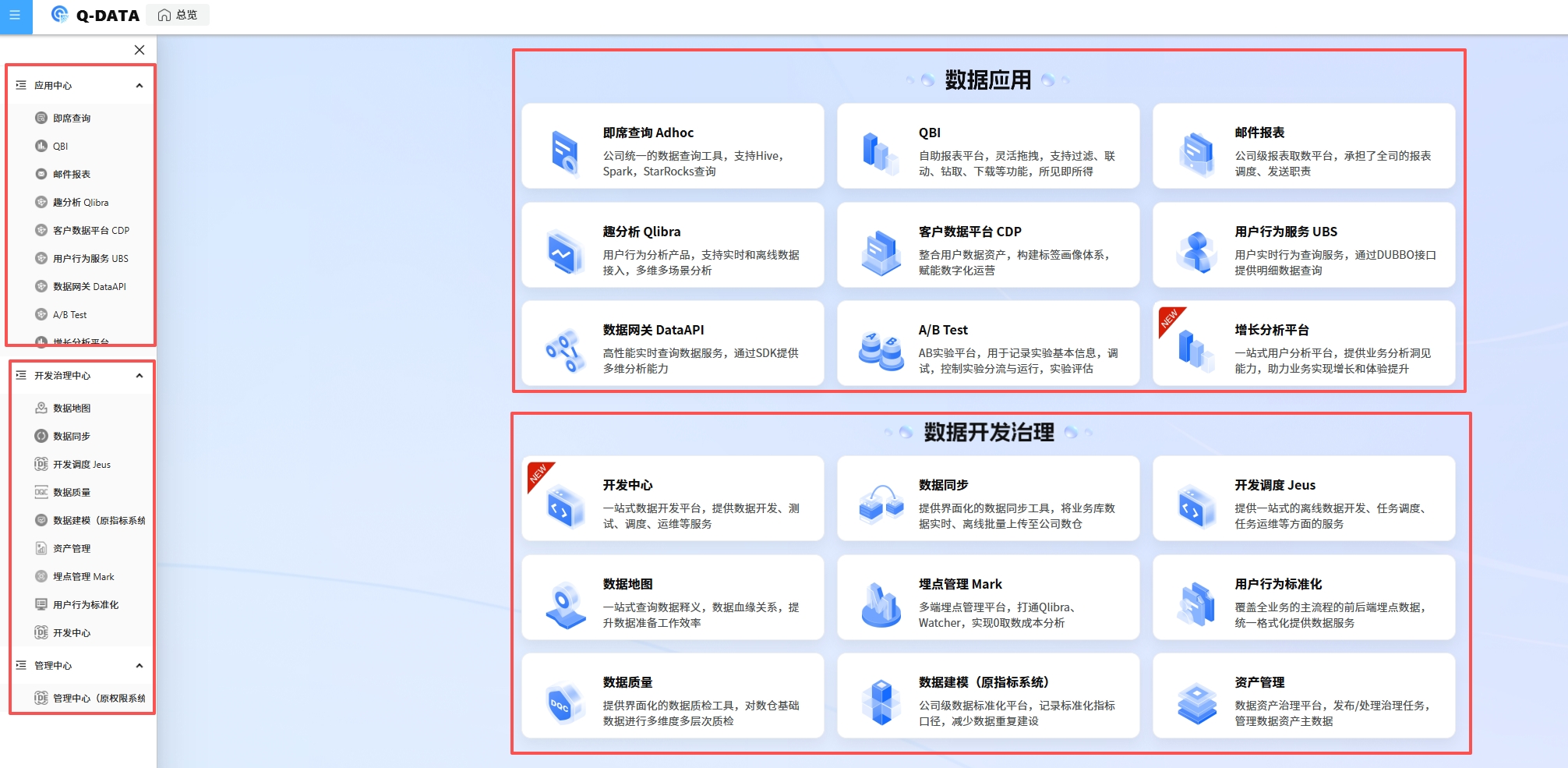
## 数据应用层
| Q-DATA模块 | 开源项目 | 商业产品 | 使用场景 |
| ----------------- | --------------------------------------- | --------------------------------------------- | ------------------------------------------ |
| 即席查询 Adhoc | Hue, Apache Zeppelin, Jupyter, Superset | Databricks SQL, AWS Athena, Google BigQuery | 数据分析师临时写SQL查数据,比如"查一下上周北京地区的订单量" |
| QBI (报表平台) | Apache Superset, Metabase, Redash | Tableau, Power BI, Looker, QuickSight | 业务人员自己拖拽配置日报/周报,不用求数据团队,比如销售日报、GMV看板 |
| 邮件报表 | Apache Superset (内置), Grafana (告警) | Tableau Server, Power BI Service | 每天早上8点自动把昨日核心数据报表发到老板邮箱 |
| 趋势分析 Qlibra | Apache Druid + Superset, ClickHouse | Mixpanel, Amplitude, Google Analytics 360 | 分析用户行为趋势,比如"过去30天每日活跃用户数变化"、"哪个功能留存率最高" |
| 客户数据平台 CDP:Tagger | Apache Unomi, RudderStack | Segment, mParticle, Adobe CDP, Salesforce CDP | 统一管理用户画像,比如"这个用户是25岁女性,看过3次商品A,属于高价值用户" |
| 用户行为服务 UBS | Apache Druid, ClickHouse, Pinot | Snowplow, Segment, Treasure Data | 实时查询用户行为,比如"这个用户刚才点了什么按钮"、"用于实时推荐" |
| 数据网关 DataAPI | Apache APISIX, Kong, Tyk | Apigee, AWS API Gateway, Azure API Management | 把数据封装成API给前端/APP调用,比如"查询商品评分接口"、"用户标签查询接口" |
| A/B Test | Unleash, GrowthBook, Flagsmith | Optimizely, LaunchDarkly, Split.io, VWO | 测试新功能效果,比如"红色按钮和蓝色按钮哪个转化率高"、"两种推荐算法哪个更好" |
| 增长分析平台 | Metabase, Superset + Jupyter | Amplitude Analytics, Mixpanel, Heap | 分析业务增长情况,比如"用户从哪个渠道来转化最好"、"漏斗哪一步流失最严重" |
## 数据开发治理层
| Q-DATA模块 | 开源项目 | 商业产品 | 使用场景 |
| ------------------------------------------------------- | ---------------------------------------------------- | ------------------------------------------------------- | ------------------------------------------ |
| 开发中心 | Apache Zeppelin, Jupyter, VS Code | Databricks Workspace, AWS Glue Studio, DataGrip | 数据工程师写代码开发数据处理任务,比如写Spark任务清洗日志数据 |
| 数据同步<br>http://dw.corp.qunar.com/fe/DataSync/taskManage | Apache NiFi, DataX, Airbyte, Debezium | Fivetran, Stitch, Talend, Informatica | 把MySQL订单表、埋点日志自动同步到数仓,实时或定时抽取 |
| 开发调度 Jeus | Apache Airflow, Oozie, DolphinScheduler, Azkaban | Prefect Cloud, Dagster Cloud, AWS Step Functions | 定时执行数据任务,比如"每天凌晨2点跑昨日汇总报表"、"任务A完成后自动执行任务B" |
| 数据地图 | Apache Atlas, DataHub, Amundsen, OpenMetadata | Collibra, Alation, Informatica EDC, Azure Purview | 搜索数据资产,比如"订单金额这个字段在哪张表"、"这个表的负责人是谁" |
| 埋点管理 Mark | - | Segment Protocols, Google Tag Manager 360, Adobe Launch | 统一管理埋点规范,比如"点击购买按钮要上报哪些字段"、"埋点文档和监控" |
| 用户行为标准化 | - | Segment Protocols, RudderStack Tracking Plans | 规范化埋点数据,比如"Android和iOS的点击事件字段统一"、"保证数据质量" |
| 数据质量 | Great Expectations, Deequ, Apache Griffin, Soda Core | Monte Carlo, Bigeye, Datafold, Anomalo | 监控数据异常,比如"今天订单量突然为0触发告警"、"某字段空值率超过阈值" |
| 数据建模(标签) | - | Segment Personas, mParticle Audiences, Lytics | 构建用户标签体系,比如"用户价值分层"、"用户兴趣偏好"、"RFM模型" |
| 资产管理 | Apache Atlas, DataHub, Amundsen | Collibra, Alation, Informatica EDC, data.world | 管理数据资产全貌,比如"公司有多少张表"、"哪些是核心资产"、"血缘关系追踪" |
## 补充说明
**底层存储计算引擎** (图中未直接展示但被引用):
- **存储**: [[HDFS]], S3, [[OSS]] / Amazon S3, Azure Blob, Google Cloud Storage
- **计算**: [[Spark]], [[Flink]], [[Hive]], [[Presto]], [[ClickHouse]] / Databricks, Snowflake, BigQuery
- **实时**: [[Kafka]], Flink, Pulsar / Confluent, AWS Kinesis, Azure Event Hubs
- **OLAP(在线分析处理)**: Druid, ClickHouse, Doris, StarRocks / Snowflake, BigQuery, Redshift
这个技术栈体现了现代数据平台"湖仓一体"的架构理念,涵盖了数据集成、开发、治理、分析的全生命周期管理。